
Message boards : Number crunching : Imbalance between Subprojects
Message board moderation
Previous · 1 · 2 · 3 · Next
| Author | Message |
|---|---|
|
Send message Joined: 18 Dec 15 Posts: 1980 Credit: 160,778,893 RAC: 37,548 |
Yes, if we can agree on what is wanted ... I guess this is rather clear, isn't it? |
|
Send message Joined: 27 Sep 08 Posts: 939 Credit: 781,720,580 RAC: 72,219 |
I would like to do about the same for each sub project, or as I said before whatever priorities the scientists need. |
 Laurence LaurenceSend message Joined: 20 Jun 14 Posts: 431 Credit: 255,399 RAC: 42 |
I would like to do about the same for each sub project, or as I said before whatever priorities the scientists need. What metric is the same? tasks, wall time, cpu time, credit or other? Forget about the scientists :) We have to assume that they always have work and that to them it is the most important thing ever. The person who prioritizes ATLAS tasks over CMS or vice versa is a brave (or stupid) person. :) In the cases where the machine is dedicated to one application, there is nothing to do. For the machines that are shared, how it is shared should be decided by the machine owner. In the absence of anything BOINC just does what it does, it may not be the best but it does work and nobody can complain that we are biassed. |
|
Send message Joined: 15 Jun 08 Posts: 2745 Credit: 302,490,732 RAC: 70,467 |
I vote for this order: 1. wall time 2. # of WUs Comments: Wall time is sometimes different between my host's scheduler request and the value on the CERN website. It should be investigated why. Multicore wall time should be calculated: raw wall time * # of used cores # of WUs should be used if wall time calculation or transfer is unreliable The following metrics shouldn't be used: CPU time is unreliable if errors occure, e.g. repeated uploads (CMS) Credits are a "moving target" as the calculation is based on too much parameters that change from WU to WU. Each subproject should get it's own switch for # of CPUs (to prepare for more multicore apps) Each subproject should get it's own switch for Max # of WUs Each subproject should get a priority value field (default 100; same function as users know from the BOINC client but based on the metric above) Each subproject should have a new switch: "normal" vs. "backup"; send backup work only if normals don't have work The standard switch ON/OFF shouldn't be removed |
|
Laurence Send message Joined: 20 Jun 14 Posts: 431 Credit: 255,399 RAC: 42 |
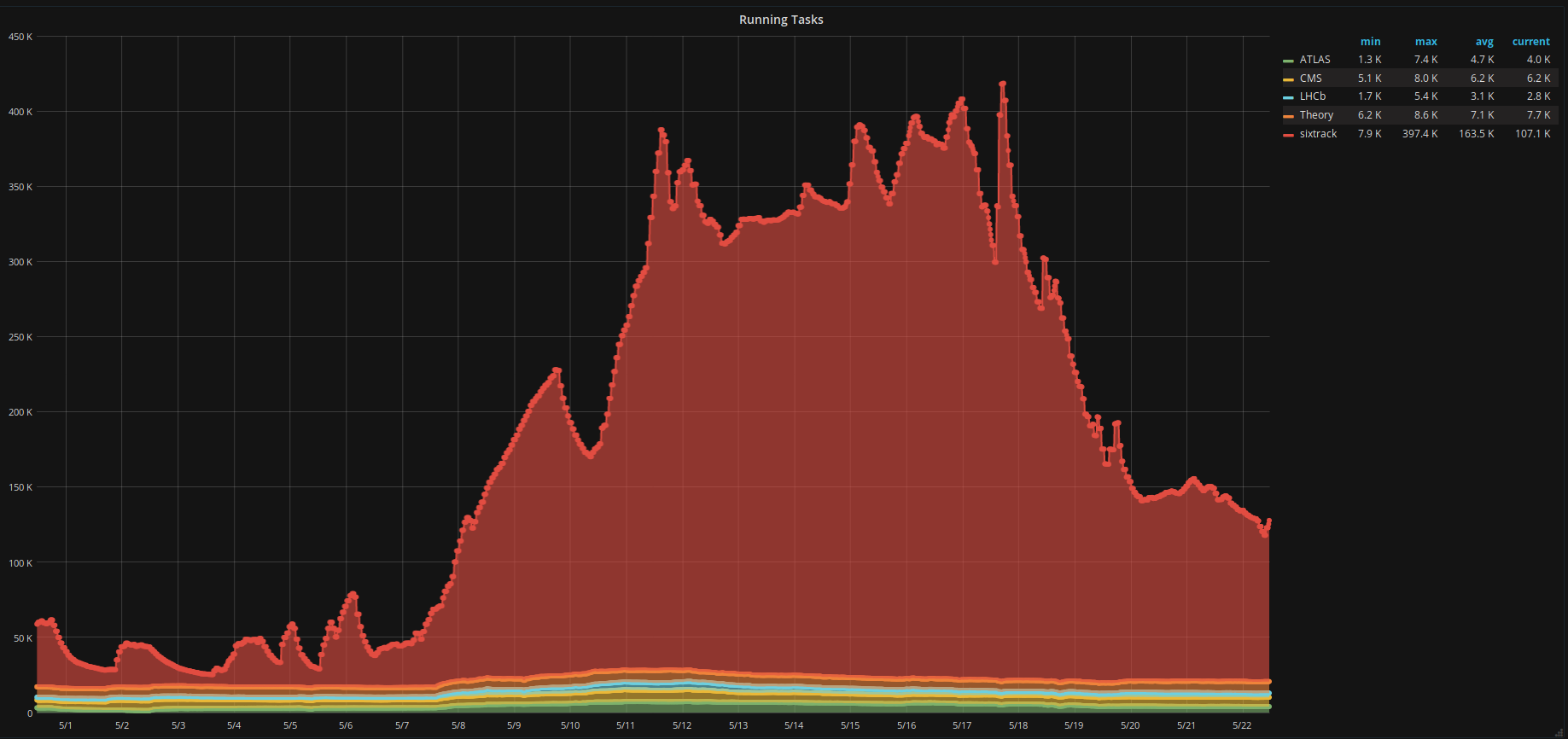
On thing that I forgot to highlight is that the scientist (application) is concerned with the overall usage and throughput rather than an individual machine. Looking at the plot from the 8th BOINC Pentathlon, you can see the large number of Sixtrack tasks and the lasagne of VM tasks at the bottom. This suggests to us that the default scheduling is sufficient. The VM applications are all at the same level and it is possible to pump out a large number of Sixtrack tasks. Our concern at the moment is that the total number of VM tasks that we run is much smaller than the number of classic tasks. Rather than optimising on a few percentage of difference with the sharing of resources, we should focus on being able to exploit an order of magnitude more resources. So in summary, project level scheduling seems to be ok for us and what would be great is if more volunteers could run VM applications. What is the limitation? Improving the sharing of individual machines would be important for some volunteers and we can try to make improvements in this area but it will not necessarily make a big difference to the overall project. Of course have happy volunteers is very important for the health of a project so it is something that should be addressed. |
|
Send message Joined: 28 Sep 04 Posts: 803 Credit: 65,621,680 RAC: 21,922 |
computezrmle's suggestions sound very good to me. 
|
|
Send message Joined: 27 Sep 08 Posts: 939 Credit: 781,720,580 RAC: 72,219 |
Tasks I think. If you think it's OK then I'm happy. It would be intresting to know why less people use the VM, computer resorces? |
|
Send message Joined: 14 Jan 10 Posts: 1552 Credit: 10,073,106 RAC: 716 |
So in summary, project level scheduling seems to be ok for us and what would be great is if more volunteers could run VM applications. What is the limitation? The main limitation for most crunchers in my opinion: "It's not set and forget". |
|
Send message Joined: 24 Jul 16 Posts: 88 Credit: 239,917 RAC: 0 |
The original boinc philosophy was to use the power of the idle cores of volunteer's computer with low priority. But it appears LHC projects need more than this statement. The standard of most of public computer is about 4 cpus and 4 GBytes RAM, even if we start to see 8 cpus and between 6 and 8 GBytes ram associated. More the requirements of the projects are far from this target and more the difficulty is big for the volunteer to suit and run them. Not everyone has the amount of money to buy a gamer configuration for his personal use or the skillness to build it and / or to add ram memory. The volunteer wants ,first of all to keep his computer responsive,when he uses it. Not everyone has a dedicated host to crunch only boinc projects. ---------------------------------------------------------------------------------------------------------------------------------------------------------------- Maybe a public inquiries (sent by boinc message to be completed by volunteers) could give datas and informations on the people who crunch LHC project. For instance : Man , Woman Student , Worker , retired Where he learns about the possibility to run lhc projects (tv , magazines , social network , newspaper ,...)? Does the computer bought only for crunch? Does he crunch at home , at work , or both ? Does he find clear , or not the instructions on the site ? Does he use the forum ? How does he evaluate his skillness (beginner , medium , pro)? Does he install boinc as a service ? Does he encounter troubles during running ? Was it about the OS platform , the virtualbox manager , the internet service provider , the app_config )? Does he crunch other project ? Does he know virtualbox ? Does he use it elsewhere ? And so on... The results of the inquiries may teach you some hidden facts , and bring a work to solve them.More you know about your volunteers (distribution and behavior), more you can understand and help them. ---------------------------------------------------------------------------------------------------------------------------------------------------------------- Theory tasks should be advised to beginners because they accept the shutdown and the reboot without any trouble and require the less ram memory. And only 1 cpu and 1 job the first time. By the way , some improvements should be made , about the RAM requirements. Apparently , it is possible to run the theory , CMS , and LHCb tasks with less ram memory than defined by default.(with no errors and the duration of internal jobs was not longer)(Is 2048 MBytes a remnant of xp OS ?). Modifying and reducing the default setting may prevent the beginner volunteer's host to be saturated. But if default values are necessary , let inform the well skilled crunchers to increase it in their app_config.xml file. It could enable more people to feel the first instant , more comfortable. They have to trust in themselve and have the good feeling that they can do it without fear.If the computer becomes unresponsive , they don't go further... |
|
Send message Joined: 9 May 09 Posts: 17 Credit: 772,975 RAC: 0 |
So in summary, project-level scheduling seems to be OK for us and what would be great is if more volunteers could run VM applications. What is the limitation? Laurence, The big issue for me (which also chimes with Philippe's comment in the immediately preceding post regarding the original DC philosophy) is that running any of the LHC sub-projects bar SixTrack seems to require an investment in additional time and resources beyond that which your average cruncher is prepared to proceed ... albeit "average" doesn't come near to describing some of the serious crunchers on LHC@Home ;-) Specifically, and in order to run multiple instances of one or more sub-project WUs, I've found that this means: - significant amounts of RAM for each machine (8GB seems to be a practical minimum; 32GB is better if the machine can take it) in order to run more than one single-core VM at a time and also use each machine for anything practical at the same time - a large monthly data download allowance (ATLAS chews through 150-200GB per WU; CMS isn't far behind with its multiple jobs per session) - fairly significant CPU power (to get the WU results back within a reasonable timescale) - a robust computer set-up which can be optimised and left to run of its own devices (as noted above by Crystal Pellet) without encountering a periodic dearth of work (due to connection glitches with CERN servers) or periodic failures with the WUs it receives (bad batches of work) On this basis, none of the sub-projects could be said to supply "rock solid" and "always available" work at a low TCO! All of this costs your average cruncher in terms of money to acquire the hardware, electricity and bandwidth allowances (hence more money) to operate it and also requires a degree of monitoring (time) which is more than most people are prepared to invest. Now I know that some of the above criticisms could be levelled at any number of other BOINC projects so it's not unique to LHC@Home. However, allowing crunchers to optimise the balance for their individual machines might go some way to encouraging more people to run the LHC VM-based sub-projects rather than just sitting around waiting for SixTrack WUs. Dave |
|
Send message Joined: 9 May 09 Posts: 17 Credit: 772,975 RAC: 0 |
- a large monthly data download allowance (ATLAS chews through 150-200GB per WU; CMS isn't far behind with its multiple jobs per session) Correction ... that should be "150-200MB per WU" (but that's still a lot given that I get through one ATLAS WU per hour per day). |
|
Laurence Send message Joined: 20 Jun 14 Posts: 431 Credit: 255,399 RAC: 42 |
The main limitation for most crunchers in my opinion: "It's not set and forget". Why not? When do you have to intervene? We would really like this to just work out of the box so please let us know the reasons why it doesn't. |
|
Laurence Send message Joined: 20 Jun 14 Posts: 431 Credit: 255,399 RAC: 42 |
The original boinc philosophy was to use the power of the idle cores of volunteer's computer with low priority. A computer has RAM, Storage and Network in addition to CPU and we would like to use all those resources. This my differ from the original philosophy but it is still volunteer computing and technology changes over time. For example today with people watching TV online, home residential networks have the capacity to do more data intensive computations.
The specification of the HEP jobs is 2GB per core. This is what is needed to do the science. In addition the applications only run on Linux and require 64bits. Sixtrack is different as their application models the accelerator itself rather than the collisions. The other constraint is that LHC@home has to fit into the overall computing infrastructure that we have. For more details, you may be interested in this presentation that I gave on the computing challenge.
We do not expect people to buy machines specifically for this. If we go down this route we should have a sponsor a machine in our data center program :) However, we would be happy if 1 core of that 4 core machine could be put to use between 5pm and 9am.
This has been studied by the Citizen Cyberlab. [/list] |
|
Laurence Send message Joined: 20 Jun 14 Posts: 431 Credit: 255,399 RAC: 42 |
Agreed and we would like to make this easier.
We would like to make this "rock solid" to at least reduce the time that people are investing. |
|
Send message Joined: 15 Nov 14 Posts: 602 Credit: 24,371,321 RAC: 0 |
It has been rock solid for me for several weeks, and I have not had any work shortages. But I run it on a dedicated Ubuntu machine with 32 GB memory, which I don't reboot very often. Any errors have cleared themselves up; no problems with VirtualBox. https://lhcathome.cern.ch/lhcathome/results.php?hostid=10477864 |
|
Send message Joined: 14 Jan 10 Posts: 1552 Credit: 10,073,106 RAC: 716 |
The main limitation for most crunchers in my opinion: "It's not set and forget". I don't have reasons for my own (not the average cruncher), but what I've seen here and read on other fora
b. VirtualBox in the BOINC package is too old, so one has to download and install VBox yourself (incl. Extension pack). A lot of crunchers are reluctant to install other software besides of BOINC. c. BOINC sometimes set vbox disabled and does not correct this after Vbox is installed. d. When no jobs available for a VM, BOINC task creates an error in spite of the volunteers host is functioning well.
|
|
Send message Joined: 18 Dec 15 Posts: 1980 Credit: 160,778,893 RAC: 37,548 |
It has been rock solid for me for several weeks, and I have not had any work shortages. But I run it on a dedicated Ubuntu machine with 32 GB memory, which I don't reboot very often. Similar situation with me - I run 2 GPUGRID tasks + 8 LHC@Home tasks on a dedicated machine (Windows) with a 6+6(HT) core processor, and 32GB RAM. In addition, both projects are run on 3 smaller PCs as well, plus 1 CMS even on a 4GB notebook. Of course, time dedication needs more than just "set and forget" which I would not be so much interested in anyway. Everything together needs close watching from time to time, and turning some screws now and then - only this makes it interesting :-) |
|
Yeti Send message Joined: 2 Sep 04 Posts: 468 Credit: 224,921,321 RAC: 9,644 |
Laurence, sorry that I have to say the following sentences, but you have asked for it:
 Supporting BOINC, a great concept ! |
|
Send message Joined: 18 Dec 15 Posts: 1980 Credit: 160,778,893 RAC: 37,548 |
Ahh, I nearly forgot: LHC@Home is a project that spends very low credits in compare to other projects ... that's what I was wondering about to begin with. What's the reason for this? You could change this by lifting up the credits for running VMs I fully endorse |
|
Laurence Send message Joined: 20 Jun 14 Posts: 431 Credit: 255,399 RAC: 42 |
This is something that we can't work around. We did have a look at Hyper-V for Windows but just end up in the same situation. The only hope is that the HEP Software Foundation comes up with some new algorithms that are better for us.
This is something that can and should be fixed.
Does this still happen? I thought this bug was fixed?
This should be resolved with the auto kill switch we recently added.
Yes and no. There will aways be situations where it doesn't work first time and the check list will help identify where the issue is. However, resorting to this should be the exception rather than the rule. |
{kind=link}

©2026 CERN