
Message boards : CMS Application : Larger jobs in the pipeline
Message board moderation
Previous · 1 · 2 · 3 · Next
| Author | Message |
|---|---|
|
Send message Joined: 14 Jan 10 Posts: 1544 Credit: 10,059,531 RAC: 1,762 |
Yesterday I had 3 VMs running. After each had done 3 jobs (20000 events/job), I didn't got new jobs at that moment and decided to shutdown the VM's gracefully and the PC could go to sleep overnight. @Ivan: How BOINC-CMS is setup now, running larger jobs will result in waste of cpu-power for the slower machines. Example: see post from computezrmle before this one. 1 job needs 11 hours. Normally a second is started, because 12 hours is not over yet., but after 18 hours this second running job is killed before the finish. Would the 1st job has been 40000 events the job would have been totally useless. I recommend to setup BOINC like it's done with Theory some years ago. Only run 1 job during BOINC's VM lifetime. |
|
Send message Joined: 15 Jun 08 Posts: 2726 Credit: 300,549,919 RAC: 57,342 |
Are you sure that each VM ran 3 of those large jobs? To me it looks like each VM ran 1 job. 20000 events within 18500 (CPU) seconds seems to be a normal value. https://lhcathome.cern.ch/lhcathome/result.php?resultid=342364179 https://lhcathome.cern.ch/lhcathome/result.php?resultid=342364448 https://lhcathome.cern.ch/lhcathome/result.php?resultid=342364474 The reason why my i7-3770K is "slow" (walltime) is mainly caused by a wanted overload controlled by systemd/cgroup slices and many other tasks running concurrently. |
|
Send message Joined: 14 Jan 10 Posts: 1544 Credit: 10,059,531 RAC: 1,762 |
Are you sure that each VM ran 3 of those large jobs?Yeah, I'm sure. I had three Consoles running on my laptop to see the progress of the 3 remote VM's and wanted to know how many events in 1 job exist, cause Ivan was talking about "2" and "4"-hour jobs. Therefore I could see that on all three Vm's new cmsrun's started twice. I changed my 'old' i7-2600 into an i9, you may have discovered ;) Besides of that from the 20 threads (10 cores), I had only 3 running except the first hours. There I had 4 threads in use for covid https://covid.si/en/stats/ Client ID: 7d61f743-caf6-ba70-c394-947e33ae4064 (third page) The rest idle for the most of the time. |
|
Send message Joined: 15 Jun 08 Posts: 2726 Credit: 300,549,919 RAC: 57,342 |
Would you mind running another one and compare #processed records on console 2 against the runtime shown for cmsRun on console 3? This should give the processing rate as records/minute (after a while to be more accurate). from the 20 threads (10 cores), I had only 3 running except the first hours. ... The rest idle for the most of the time This would - at least partly - explain extremely high processing rates. |
|
Send message Joined: 2 May 07 Posts: 2290 Credit: 178,874,044 RAC: 2,627 |
After 6 hours 20k is done. Seeing this info in masterlog every 5 Minutes: 02/03/22 15:39:59 (pid:16256) CONFIGURATION PROBLEM: Failed to insert ClassAd attribute GLIDEIN_Resource_Slots = Iotokens,80,,type=main. The most common reason for this is that you forgot to quote a string value in the list of attributes being added to the MASTER ad. 02/03/22 15:39:59 (pid:16256) CONFIGURATION PROBLEM: Failed to insert ClassAd attribute STARTD_JOB_ATTRS = x509userproxysubject x509UserProxyFQAN x509UserProxyVOName x509UserProxyEmail x509UserProxyExpiration,MemoryUsage,ResidentSetSize,ProportionalSetSizeKb. The most common reason for this is that you forgot to quote a string value in the list of attributes being added to the MASTER ad. 02/03/22 15:39:59 (pid:16256) CONFIGURATION PROBLEM: Failed to insert ClassAd attribute STARTD_PARTITIONABLE_SLOT_ATTRS = MemoryUsage,ProportionalSetSizeKb. The most common reason for this is that you forgot to quote a string value in the list of attributes being added to the MASTER ad. |
|
Send message Joined: 14 Jan 10 Posts: 1544 Credit: 10,059,531 RAC: 1,762 |
Would you mind running another one and compare #processed records on console 2 against the runtime shown for cmsRun on console 3?You seem hard to be convinced ;) From the finished_1.log: Begin processing the 1st record. Run 1, Event 59740001, LumiSection 119481 on stream 0 at 03-Feb-2022 15:18:56.085 CET . Begin processing the 10001st record. Run 1, Event 59750001, LumiSection 119501 on stream 0 at 03-Feb-2022 16:07:05.436 CET . Begin processing the 20000th record. Run 1, Event 59760000, LumiSection 119520 on stream 0 at 03-Feb-2022 16:54:06.629 CET CPU time from cmsRun 93:34:19 |
|
Send message Joined: 2 May 07 Posts: 2290 Credit: 178,874,044 RAC: 2,627 |
process id is 391 status is 0. Now 7 hours including the last 15 #min. idle. Waiting now for ending or a second task. |
|
Send message Joined: 14 Jan 10 Posts: 1544 Credit: 10,059,531 RAC: 1,762 |
@Ivan: The contents of wmagentJob.log only shows the running job. The previous job info is overwritten. Could you create wmagentJob_1.log, wmagentJob_2.log etc, if you stick to running more jobs in 1 VM-lifetime. Or just append the info of the 2nd, 3rd etc job to 1 wmagentJob.log |
|
Send message Joined: 15 Jun 08 Posts: 2726 Credit: 300,549,919 RAC: 57,342 |
You seem hard to be convinced ;) Just impressed ;-D |
|
Send message Joined: 29 Aug 05 Posts: 1153 Credit: 11,734,920 RAC: 297 |
It appears that the tasks currently in the queue are running jobs with 20000 records (before: 10000) and that the tasks shut down after 1 job (before: more than 1). It's a result of the various limits, I think. Thanks for the feedback.  |
|
Send message Joined: 29 Aug 05 Posts: 1153 Credit: 11,734,920 RAC: 297 |
After 6 hours 20k is done. I've been told that that is not a problem per se and it doesn't affect the jobs. Still, it'd be nice to be rid of it... |
|
Send message Joined: 29 Aug 05 Posts: 1153 Credit: 11,734,920 RAC: 297 |
@Ivan: The contents of wmagentJob.log only shows the running job. The previous job info is overwritten. I'll ask Laurence, that's his area of responsibility. |
|
Send message Joined: 29 Aug 05 Posts: 1153 Credit: 11,734,920 RAC: 297 |
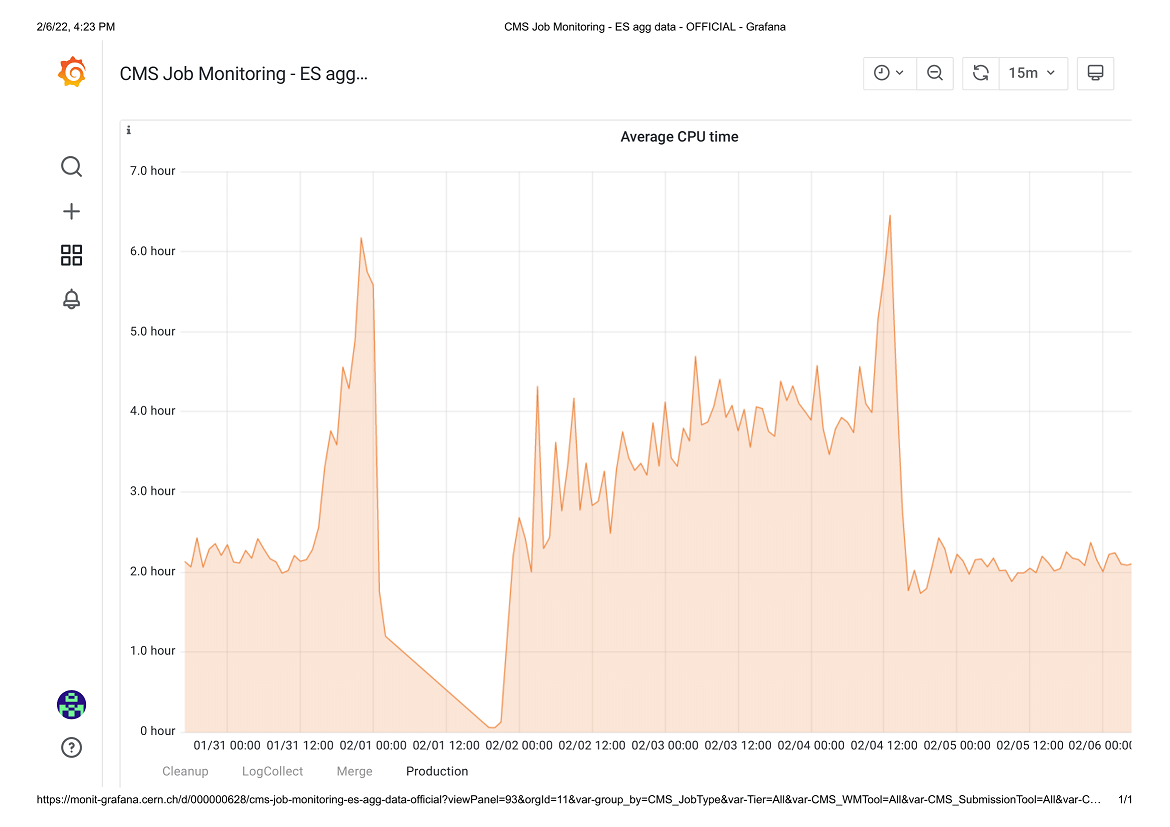 The graph of average job time over several days is instructive, a) At around 1200 on 31/1 we ran out of jobs as we drained the queues for the WMAgent update. Before that, the 10,000-event jobs were showing an average of just over 2 hours. As the faster machines ran out of jobs, the average job time increased as slower machines reported in with longer run times. By the time the update was started, the remaining few very slow machines were averaging over 6 hrs/job. b) On the 1/2 I ran some large jobs from a workflow we are investigating, but its run-times were too short for our purposes -- 5 minutes to produce 60 MB of output. c) I then started "four-hour" jobs, of 20,000 events which started running about 2000 on 1/2. You can see that the fastest machines reported run-times of around two hours, but the average then crept slowly up to four hours as the slower machines started reporting in. d) When I submitted 40,000-event jobs, they didn't run because of a time-to-run mismatch in condor (1200 on 4/2). Again, as the queue drained the average time started increasing as the fastest machines dropped out of the reporting. e) When I submitted 10,000-event jobs again on 5/2, the average quickly stabilised to the long-term value of two hours. The graph below shows a histogram of run-times for a batch of 10,000-event jobs. 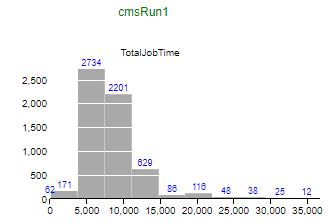 We need to fold these observations into our configurations as we move forward.[/img] |
|
Send message Joined: 29 Aug 05 Posts: 1153 Credit: 11,734,920 RAC: 297 |
@Ivan: The contents of wmagentJob.log only shows the running job. The previous job info is overwritten. I'm told this will be implemented tomorrow. |
|
Send message Joined: 14 Jan 10 Posts: 1544 Credit: 10,059,531 RAC: 1,762 |
Thanks Ivan (and Laurence).@Ivan: The contents of wmagentJob.log only shows the running job. The previous job info is overwritten. Are you considering to move to "4-hour" jobs again in the near future or even to the CMS-standard of 40,000 events ("8-hour job"). If the latter: Have a talk with Laurence, whether it's possible somehow to get rid of the VM-minimum liftetime of 12 hours and the max of 18 hours. In my opinion it would be better, when running the avg 8 hour-jobs, to only run 1 job with 1 BOINC-task. Maybe it.s even possible to send the CMS-job with the BOINC-task to the client and no longer requesting the job by the Virtual Machine, because it's already in the shared directory then. |
|
Send message Joined: 29 Aug 05 Posts: 1153 Credit: 11,734,920 RAC: 297 |
Are you considering to move to "4-hour" jobs again in the near future or even to the CMS-standard of 40,000 events ("8-hour job"). Not in the immediate future. It was an exploratory exercise in anticipation of a request from formal production. If/when that happens, we will surely make adjustments such as you suggest to better cope with the varied volunteer resources. As I think you know, we do run benchmarks at the start of each task, but there's no way that I'm aware of that we can feed that back -- ultimately to WMAgent -- to tailor the number of events per job to the power of the machine at hand. |
|
Send message Joined: 29 Aug 05 Posts: 1153 Credit: 11,734,920 RAC: 297 |
@Ivan: The contents of wmagentJob.log only shows the running job. The previous job info is overwritten. Anyone noticing if this is working? I though I'd left enough time for Laurence's implementation to trickle down to CVMFS, but my jobs still have only the current log in the web interface. I'm letting the project run overnight to see if the next task still has the same behavior. |
|
Send message Joined: 29 Aug 05 Posts: 1153 Credit: 11,734,920 RAC: 297 |
behavior Apologies for letting BOINC's spill-chucker bully me into using US spelling. It is, of course, "behaviour"! |
|
Send message Joined: 29 Aug 05 Posts: 1153 Credit: 11,734,920 RAC: 297 |
@Ivan: The contents of wmagentJob.log only shows the running job. The previous job info is overwritten. No, it's not working for me. The log must be deleted before the copy command is executed. I guess the logic needs a re-think. |
|
Send message Joined: 29 Aug 05 Posts: 1153 Credit: 11,734,920 RAC: 297 |
@Ivan: The contents of wmagentJob.log only shows the running job. The previous job info is overwritten. This will be debugged when time allows. |

©2026 CERN