
Message boards : Theory Application : New version 300.00
Message board moderation
Previous · 1 · 2 · 3
| Author | Message |
|---|---|
|
Send message Joined: 9 Feb 16 Posts: 50 Credit: 546,878 RAC: 0 |
Since the new version I've been getting quite a few (Virtual Box) tasks that start out normally enough, but then (after about a day) suddenly jump to an estimated time to completion of about four days. Given that my PC only crunches during office hours (ie how BOINC was intended to be used), then assuming a working day of eight hours that would equate to running for an additional 12 days, ie 13 days in total. Add in a couple of weekends (when the PC is off), and the total number of days required to complete the task will be around 17 days. This is much greater than the time allowed to complete the task. That of course means the task gets farmed out to another host, that may or may not beat my host to the finish, depending on how the host is operated. An additional concern is that since the task is behaving oddly, that might be indicative that something has gone wrong and the task will eventually fail (or run forever). Consequently I've been aborting these tasks. I aborted the first on the 9th December, and I see the host to which it was resent is still chewing on it. Are these tasks broken? If they are doing useful work I'm prepared to let them run, but only if the allowed time is greatly extended (I would suggest a month). However, I much preferred the shorter running tasks from the last version, as there is less risk of weeks of crunching being wasted on a task that fails (for whatever reason). These long-runners have an estimated time to completion that is greater than a typical CPDN task, but at least CPDN uses trickles, ensuring that work isn't completely wasted if a task fails. And CPDN allows plenty of time to complete tasks. |
|
Send message Joined: 14 Jan 10 Posts: 1540 Credit: 10,049,638 RAC: 1,414 |
Are these tasks broken? If they are doing useful work I'm prepared to let them run, but only if the allowed time is greatly extended (I would suggest a month).The average run time of a Theory VBox task is between 2 and 6 hours, although there are a few longrunners up to several days (mostly sherpa). You may watch the process by using 'Show VM Console' in BOINC Manager when you have selected a running task. VirtualBox Extension Pack must be installed for that feature. Using functionkeys ALT-F1, -F2 and -F3 in the Console (Remote Desktop) shows 1 the startup and job-description at the end, 2 the progress of event processing (mostly up to 100000) and 3 cpu-usage of the processes in your VM. In your result logs, I see that a task is restarted sometimes. Shutting down your machine when you have Vbox-tasks running needs some attention. First stop the BOINC client and wait a few minutes to give a VM time to save their contents to disk before shutting down the host. |
|
Send message Joined: 18 Dec 15 Posts: 1971 Credit: 159,521,981 RAC: 47,457 |
[quote] there are a few longrunners up to several days (mostly sherpa).These Sherpa seem to be somewhat unsafe, anyway. I had such one about a week ago, the task ran for about 3 days, then it got finished and was uploaded, but it turned out being unvalid for some reason. So what I decided for myself: whenever I see such a task runnig vor more than about 20 hours, and it's Sherpa, I will discontinue it. |
|
Send message Joined: 9 Feb 16 Posts: 50 Credit: 546,878 RAC: 0 |
I always shut down BOINC gracefully before shutting down the PC, but not when I hibernate the PC (every night). I've not had any problems with Theory tasks until now. When I ran out of time on the first long-runner, I did take a look with the console. It was Sherpa and it did appear to be hard at work doing something. But it was already well out of time and still had (from memory) well over a day (of CPU time) to complete, which is why I aborted it. That seems to be the only option to avoid the risk of weeks of wasted crunching. As best I can tell from the task report not all those I have aborted were Sherpa, but all of them had an estimated completion time of about four days. |
|
Send message Joined: 14 Jan 10 Posts: 1540 Credit: 10,049,638 RAC: 1,414 |
....., but all of them had an estimated completion time of about four days.The estimation life time of a job is for all tasks 100 hours when it has run for a while. Then every 1% of progress the time left goes down an hour, but this is BOINC and has totally nothing to do with the job run time inside the VM. So ignore % progress and time left in BOINC Manager and only look what the Consoles are telling you. There you can make up your mind, whether it's valuable to try to finish a task or not. |
|
Send message Joined: 9 Feb 16 Posts: 50 Credit: 546,878 RAC: 0 |
OK, thanks, I'll try that. I have a Sherpa task running now that says in the VM console integration time: (3h 4m 22s elapsed / 1h 5m 18s left), but BOINC manager says the remaining time is nearly 4 days. I'll leave it to run and see which matches reality. |
 Magic Quantum Mechanic Magic Quantum MechanicSend message Joined: 24 Oct 04 Posts: 1294 Credit: 95,313,098 RAC: 26,682 |
I have done many of these that are from 2 days to as long as 9 days and usually are Valid or Pending (Theory and Sixtrack) BUT I was watching this 100 hour task finish and it was starting to do the run at 100% and after a couple usual minutes instead of sending it in it became an Error (and long waste of time) https://lhcathome.cern.ch/lhcathome/result.php?resultid=254726342 </stderr_txt> <message> upload failure: <file_xfer_error> <file_name>Theory_2279-752223-192_0_r1270742450_result</file_name> <error_code>-240 (stat() failed)</error_code> </file_xfer_error> </message> ]]> I have lots of them running but I sure hope I don't get any more like that one since most of my running tasks are the long ones that have to be done when they say they will be since it is on the final due date/time |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1294 Credit: 95,313,098 RAC: 26,682 |
Oy Vey https://lhcathome.cern.ch/lhcathome/result.php?resultid=254726341 Another one cranky: [WARNING] 'cvmfs_config probe sft.cern.ch' failed. (and after that they ran for 100 hours) Run time 4 days 4 hours 7 min 33 sec (100%) CPU time 27 min 7 sec Validate state Invalid Credit 0.00 <message> upload failure: <file_xfer_error> <file_name>Theory_2279-800666-192_0_r1155160780_result</file_name> <error_code>-240 (stat() failed)</error_code> </file_xfer_error> </message> I might just abort any other two I have running and just stick to the long Sixtrack tasks here and the long Theory-dev version (or was the server down for a couple hours for these version 300.00 problems? ) |
|
Send message Joined: 14 Jan 10 Posts: 1540 Credit: 10,049,638 RAC: 1,414 |
@MAGIC QM: That errors are caused by a network failure and not possible to use local CVMFS The latter cranky: [INFO] Creating local CVMFS repository. Guest Log: sed: can't read cvmfs-mini-0.1-amd64.tgz: No such file or directory Guest Log: tar: option requires an argument -- 'f' Guest Log: Try `tar --help' or `tar --usage' for more information. Guest Log: /home/boinc/cranky: line 62: ./cvmfs-mini-0.1-amd64/mount_cvmfs.sh: No such file or directory cranky: [WARNING] 'cvmfs_config probe sft.cern.ch' failed.should be investigated by the admins and was reported earlier. I would not let them run for over 4 days with such a low CPU-usage. |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1294 Credit: 95,313,098 RAC: 26,682 |
I have so many of these running at the same time that I don't see every one boot up but I do check them when I do start them myself (most members here wouldn't do that of course) But I should have checked them earlier so I could see they got the cranky-fail message (they should not be able to run for that long if they start off with that error and then fake run for as long as 100 hours) Since I have been watching them all start (over at dev with a different version) I check and make sure they start up without that cranky error and instead look like this..... 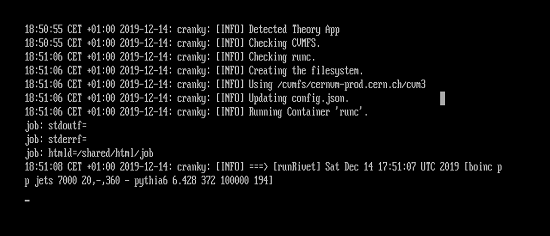 And no matter how long they run they are Valids (longest so far is 19 hours) |
|
Send message Joined: 9 Feb 16 Posts: 50 Credit: 546,878 RAC: 0 |
How am I supposed to know from the following VM console output if this long-runner is doing anything useful? 0.0918751 pb +- C 0.000644023 pb = 0.700976 % ) 130000 ( 477274 -> 28.6 % ) full optimization: ( 1h 35m 44s elapsed / 2h 23m 36s left ) [09:07:Z3] Updating display. Display update finished (0 histograms, 0 events). Updating display. Display update finished (0 histograms, 0 events). Updating display. Display update finished (0 histograms, 0 events). Updating display. Display update finished (0 histograms, 0 events). Updating display. Display update finished (0 histograms, 0 events). Updating display. Display update finished (0 histograms, 0 events). Updating display. Display update finished (0 histograms, 0 events). Updating display. Display update finished (0 histograms, 0 events). 0.0920208 pb +- ( 0.000606447 pb = 0.659032 ) 140000 ( 511623 -> 29.1 %) full optimization: ( 1h 43m 11s elapsed / 2h 16m 21s left ) [09:14:58] Updating display. Display update finished (0 histograms, 0 events). Updating display. Display update finished (0 histograms, 0 events). The part that says "2h 16m 21s left" doesn't appear to represent the end point of the entire task, but rather some sub-task, and I've even less idea what the rest of the text means (other than the time in square brackets). |
|
Send message Joined: 15 Jun 08 Posts: 2725 Credit: 300,175,242 RAC: 41,020 |
It needs some experience to interpret the logfile as it is a mix from different processes. The good thing: "full optimization: ..." shows a decreasing time left and 2h + is rather short for a sherpa. Not yet done: The 1st line of the log shows the #events to be processed. This is also written to stderr.txt. Example from another task: ===> [runRivet] Sat Dec 14 05:12:22 UTC 2019 [boinc pp jets 7000 65 - sherpa 1.4.1 default 100000 194] At some point a healthy sherpa should start to show increasing #events like this: Display update finished (127 histograms, 92000 events). Now check your BOINC due date. If you have lots of time left and lots of events are already processed, let the task run. If the task doesn't make progress like the one in my example (remained at 92000 for more than a day), then cancel it. In your example: Wait until "full optimization: ..." has finished. Check every few hours if "Display update ..." shows increasing #events. |
|
Send message Joined: 14 Jan 10 Posts: 1540 Credit: 10,049,638 RAC: 1,414 |
The part that says "2h 16m 21s left" doesn't appear to represent the end point of the entire task, but rather some sub-task, and I've even less idea what the rest of the text means (other than the time in square brackets).When the final part with the real event-processing is busy you get an ETA of finish, although even in that part an endless loop may occur (not very often). The previous sub-parts often needs more time than the event processing part. During the last calculation part optimization suddenly is switched to integration. During the integration part one may even see times left increasing. Often a bad sign, but I also saw tasks then suddenly starting the event processing part. So, one never knows. Example of the sub-parts: ===> [runRivet] Mon Dec 16 06:30:30 UTC 2019 [boinc pp z1j 7000 100 - sherpa 1.4.1 default 100000 194] Setting environment... . . . Initializing HadronDecays.dat. This may take some time. . . . Starting the calculation. Lean back and enjoy ... . 6.69716 pb +- ( 0.347593 pb = 5.19015 % ) 5000 ( 7466 -> 66.9 % ) full optimization: ( 2s elapsed / 2m 49s left ) . . . Starting the calculation. Lean back and enjoy ... . 1.78967 pb +- ( 0.220667 pb = 12.3301 % ) 5000 ( 16779 -> 29.7 % ) full optimization: ( 41s elapsed / 41m 58s left ) . . . Starting the calculation. Lean back and enjoy ... . 6.66455 pb +- ( 0.288513 pb = 4.32906 % ) 5000 ( 7353 -> 67.9 % ) full optimization: ( 2s elapsed / 2m 52s left ) . . . Starting the calculation. Lean back and enjoy ... . 1.62396 pb +- ( 0.235306 pb = 14.4897 % ) 5000 ( 16683 -> 29.9 % ) full optimization: ( 39s elapsed / 40m 23s left ) . 1.72703 pb +- ( 0.00601267 pb = 0.34815 % ) 240000 ( 639844 -> 41.5 % ) integration time: ( 34m 33s elapsed / 10m 5s left ) . . . Event 100 ( 10s elapsed / 2h 53m 59s left ) -> ETA: Mon Dec 16 11:15 100 events processed . . .Don't lean back too long. Sometimes you have to get up for some drinks or food. |
|
Send message Joined: 9 Feb 16 Posts: 50 Credit: 546,878 RAC: 0 |
OK, thanks. I just aborted it, as it doesn't seem to be making any obvious progress. I don't have time for this hand-holding of tasks, and long-runners stop my host from running LHC tasks that play nicely and complete in a reasonable time. I'll just go back to aborting tasks if they switch to displaying an impossible ETA in BOINC manager. |
|
Send message Joined: 2 May 07 Posts: 2289 Credit: 178,856,613 RAC: 2,046 |
This task ended with error: 11:58:56 CET +01:00 2019-12-17: cranky-0.0.29: [INFO] ===> [runRivet] Tue Dec 17 10:58:56 UTC 2019 [boinc pp jets 8000 25 - pythia8 8.230 tune-AZ 100000 196] 16:57:39 CET +01:00 2019-12-17: cranky-0.0.29: [ERROR] Container 'runc' terminated with status code 1. 16:57:40 (8604): cranky exited; CPU time 16549.800429 16:57:40 (8604): app exit status: 0xce 16:57:40 (8604): called boinc_finish(195) https://lhcathome.cern.ch/lhcathome/workunit.php?wuid=128552075 |
|
Send message Joined: 2 May 07 Posts: 2289 Credit: 178,856,613 RAC: 2,046 |
Saw this, but native Theory running well :-): 15:21:35 CET +01:00 2019-12-28: cranky-0.0.29: [INFO] Pausing container Theory_2279-766745-200_0. 15:21:35 CET +01:00 2019-12-28: cranky-0.0.29: [WARNING] Cannot pause container as /sys/fs/cgroup/freezer/boinc/freezer.state not exists. 18:44:38 CET +01:00 2019-12-28: cranky-0.0.29: [INFO] Resuming container Theory_2279-766745-200_0. container not paused 19:50:20 CET +01:00 2019-12-28: cranky-0.0.29: [INFO] Container 'runc' finished with status code 0. |
|
Send message Joined: 14 Jan 10 Posts: 1540 Credit: 10,049,638 RAC: 1,414 |
Saw this, but native Theory running well :-):Is it also running well ;-) when the job should be suspended? |
|
Send message Joined: 2 May 07 Posts: 2289 Credit: 178,856,613 RAC: 2,046 |
VM with 4 CPU's including one Atlas-native with 2 CPU's and two Theory-native with always 1 CPU. When Atlas-native starts one task - it can be that one Theory-native is suspended from the Linux, but this Theory-native task is finishing - showing in the TOP-window. Maybe this message is from this task. |

©2026 CERN