
Message boards : Number crunching : Too Many Total Results
Message board moderation
| Author | Message |
|---|---|
|
Send message Joined: 1 Sep 04 Posts: 52 Credit: 11,767,629 RAC: 0 |
Not sure if the title lIne is the most relevant piece of information but in the last last week about half of my tasks in LHCb, CMS, and Theory are having this problem. (I'm not running Atlas.) Here's an example. https://lhcathome.cern.ch/lhcathome/workunit.php?wuid=101479827 Any ideas are appreciated. Thanks, - Dick |
|
Send message Joined: 27 Sep 08 Posts: 931 Credit: 781,167,625 RAC: 88,440 |
Looks like the vm is going on and off, this isn't ideal for the VM based work units. configure boinc to allow computer use all the time (no suspend options checked) Lower the "use at most" if you want your computer to be more responsive |
|
Send message Joined: 1 Sep 04 Posts: 52 Credit: 11,767,629 RAC: 0 |
Thank you, Toby. I'll try that. |
|
Send message Joined: 1 Sep 04 Posts: 52 Credit: 11,767,629 RAC: 0 |
That seems to have done the trick, Toby. I'll experiment with the setting and find which one(s) cause the problem. My best guess is the "computer in use" option. One more question. Was there any kind of a change in the operation of these tasks somewhere around 9/20? That's when these errors seem to have begun. Of course it's possible I fiddled with something that caused it even though I don't remember doing so. Just curious. the fact that others haven't reported this (that i've seen) probably indicates I'm guilty. Thanks again for your help. |
|
Send message Joined: 13 Apr 18 Posts: 443 Credit: 8,438,885 RAC: 0 |
If you check the "suspend if" box again AND continue your previous usage pattern then you will get more failed tasks, guaranteed. Maybe not today, maybe not tomorrow but you will eventually and there will be lots of them. Toby didn't give you a "try this, I dunno, it might work" kind of thing. He wasn't giving you a "test this unproven idea I have about how the settings work" thing. He gave you a fundamental truth about how the settings have to be if you want to get a high success rate. This is how it will go... Tasks that are running when the computer is NOT being used will NOT suspend/resume repeatedly, they will complete and verify 99% of the time unless there are other problems. Tasks that run when the computer IS being used will pause/resume repeatedly and frequently fail. Yes, there was a change around 9/20. They had (and maybe are still having) some severe infrastructure problems. I have a hunch the "Too Many Total Results" error you were happening because one of their problems (Condor canceling jobs too soon) tricked the server into thinking it was getting a number of results from a number of different hosts when in fact it was just your host pausing/resuming the same task numerous times. One of your tasks showed it paused 56 times!!! So if you check the "suspend if" box again you might get a different error but they'll still error. |
 Magic Quantum Mechanic Magic Quantum MechanicSend message Joined: 24 Oct 04 Posts: 1300 Credit: 95,694,642 RAC: 22,683 |
I have always had mine set this way. 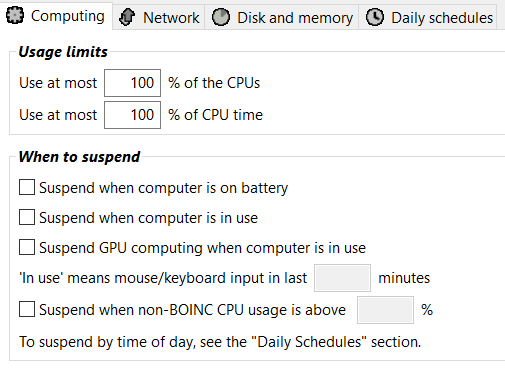 |
|
Send message Joined: 1 Sep 04 Posts: 52 Credit: 11,767,629 RAC: 0 |
Thanks, Bronco. Yup, got it. I didn't respond in sufficient detail. I wasn't planning to turn on "Suspend if computer is in use". I was thinking about the "GPU computing" (and maybe the "computer is on battery", but that's a different issue). AiUI BOINC doesn't use a GPU I figured I could turn that one on with no ill effects and I'm pretty sure it will help system performance I figure to try it and monitor it. If that works I may also try and test the battery suspend. That won't affect performance, but the machine is rarely on battery so while there may stop & resume from time from time, it won't happen frequently, probably less than once / week. On those occasions though it would be better to have BOINC quiesced if possible. I know that Toby gave me a performance work around too, changing the "Use at most..." (CPU time I presume), but I'd to see how high I can keep that and still have the machine functional for other purposes. I wish it were a dedicated box, it just isn't. I've experimented with the GPU use in the past and it seemed to make a difference. The plan is to try it and monitor it to make sure it doesn't cause problems. That make sense? Mechanic, I have my settings the same as yours except that the Use at Most CPU is at 90%. I may have to lower that further but my goal is to let it rip as much as possible and that's why I'll experiment test with the GPU suspension. Thanks, - Dick |
|
Send message Joined: 18 Dec 15 Posts: 1978 Credit: 160,515,754 RAC: 49,362 |
... and that's why I'll experiment test with the GPU suspension.as long as you don't use the GPU for computing (projects like GPUGRID, Seti@home, ...) the GPU suspension function doesn't play any role. |
|
Send message Joined: 13 Apr 18 Posts: 443 Credit: 8,438,885 RAC: 0 |
I know that Toby gave me a performance work around too, changing the "Use at most..." (CPU time I presume), but I'd to see how high I can keep that and still have the machine functional for other purposes.I could be wrong but I think he was talking about "Use at most __ % of the CPUs". Leave the "Suspend" boxes unchecked and if the machine is not functional for other purposes then set "Use at most __ % of the CPUs " to 99% which will cause BOINC to use 1 less CPU and leave 1 CPU for other purposes. That way you get the performance you need and the tasks never pause. That means crunching fewer tasks but you'll have a lower failure rate. If it's a 4 CPU machine and you need 2 CPUs for your other purposes then set it between 50% to 74% (inclusive). I wish it were a dedicated box, it just isn't. I've experimented with the GPU use in the past and it seemed to make a difference. The plan is to try it and monitor it to make sure it doesn't cause problems.With LHC tasks the monitoring is itself a problem. They're not like other projects' tasks. Here "verified" doesn't always mean a successful result. With ATLAS, for example, you can spend thousands of hours crunching and have every result verify and think you've done a ton of useful work and then discover that in spite of the tasks verifying they did not return a HITS file and therefore did nothing but waste electricity. So monitor but do remember you sometimes need to look beyond what it says in the Status column in your results list. That make sense? Not sure. It depends on what your "other purposes" are. You haven't mentioned it and nobody has asked. It might make more sense to just forget about any LHC VBox app and just do Sixtrack and other projects' apps that can handle being suspended. In the end it's your decision, your power bill and your CPU time so it only has to make sense to you. |
|
Send message Joined: 1 Sep 04 Posts: 52 Credit: 11,767,629 RAC: 0 |
With LHC tasks the monitoring is itself a problem. They're not like other projects' tasks. Here "verified" doesn't always mean a successful result. With ATLAS, for example, you can spend thousands of hours crunching and have every result verify and think you've done a ton of useful work and then discover that in spite of the tasks verifying they did not return a HITS file and therefore did nothing but waste electricity. So monitor but do remember you sometimes need to look beyond what it says in the Status column in your results list. I knew that ATLAS could return a worthless "valid" result and (with your help) learned how to check them. I've stopped running ATLAS until I have more time to work on it. I didn't know that the other virtual projects also could do that. Can you tell me how I can check them more thoroughly? Is that also done through PanDa? Not sure. It depends on what your "other purposes" are. You haven't mentioned it and nobody has asked. It might make more sense to just forget about any LHC VBox app and just do Sixtrack and other projects' apps that can handle being suspended. By "other purposes" I just meant that I use this device during the day for other things, browsing, spreadsheets, etc. I just need the make the performance not too clunky. That's why I'm attacking this as a fine tuning task. (I have another machine that's beefier and I run 6Track on it but I've never been able to get it to run anything virtual. Another project for the mythical day when there's more time.) As for "sense", i was looking to see if I so clearly was misunderstanding technical aspects that I was making no sense in that respect. Once again, thank you for taking the time to educate me. - Dick |
|
Send message Joined: 13 Apr 18 Posts: 443 Credit: 8,438,885 RAC: 0 |
I didn't know that the other virtual projects also could do that. Can you tell me how I can check them more thoroughly? Is that also done through PanDa?I'm not sure what the other apps send back to the server and I don't think there is an easy way to check it. That's my point... except for ATLAS, we can't check the output so the best/smartest thing we can do is make sure they don't suspend or get preempted at all. There might be a very difficult way to check. There are likely details of successes and failures recorded in the running logs but they are so cryptic as well as verbose most humans don't have the time or patience to pore through them. |
|
Send message Joined: 9 May 10 Posts: 14 Credit: 3,529,548 RAC: 0 |
I too am having this issue. All of them so far are CMS. 2x nodes of the following: 2x E5-2695v2 w/192GB Microsoft Windows 10 Professional x64 Edition, (10.00.19041.00) BOINC Ver: 7.16.11 Virtualbox (6.1.12) installed, CPU has hardware virtualization support and it is enabled No other projects running other than LHC@home *Have tried 60m between tasks and 6000m - no difference *No suspension settings *800GB available, 100GB~ being used. Example: https://lhcathome.cern.ch/lhcathome/result.php?resultid=289041431 |
|
Send message Joined: 15 Jun 08 Posts: 2739 Credit: 301,894,252 RAC: 83,684 |
2 48-core CPUs, 192 GB RAM each. Each CMS task runs a 2GB VM => 96 GB on each computer. RAM size shouldn't be a bottleneck. Disk speed can be a bottleneck if too many tasks start (nearly) concurrently. Internet bandwidth can also be a bottleneck if too many tasks start concurrently. A local proxy is highly recommended - especially if you run that many CMS tasks. What are your values? download: upload: ping (e.g. to cms-frontier.openhtc.io): LAN connection should be done via cable (not wi-fi), preferably 1 Gbit/s. |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1300 Credit: 95,694,642 RAC: 22,683 |
LAN connection should be done via cable (not wi-fi), preferably 1 Gbit/s. If anyone out there has 1GBps or better could you please run a cable to my place and share that speed? (and Cern will pay for that cable/fiber and I'll pay half of your monthly bill) But yes Stef is correct about having a high-speed isp to run CMS tasks even just one task let alone a entire host of threads. (even Theory tasks want a fast connection if you run lots of them like I tend to do) |
|
Send message Joined: 15 Jun 08 Posts: 2739 Credit: 301,894,252 RAC: 83,684 |
LAN (Local Area Network) != WAN (Wide Area Network) I was writing about the connectivity inside a user's household. I was not writing about the connectivity to the user's ISP. The latter might get saturated in upload direction based on the following estimations: 1. according to the CMS monitoring the average core time is around 3 h per subtask 2. each subtask generates a result file of ~120 MB Guess your upload bw is 5 Mbit/s => 56 CMS tasks would completely saturate that internet connection. That's why I ask for those values. Other possible bottlenecks (disk, RAM, ...) should also be checked. |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1300 Credit: 95,694,642 RAC: 22,683 |
Yes I think we all know that. (once again I was not asking for help) |
|
Send message Joined: 9 May 10 Posts: 14 Credit: 3,529,548 RAC: 0 |
Thanks for the reply... What do you mean when you ask what my values are? DL/UL are not throttled... There is no way to get to these machines other than wifi. Currently on an Orbi mesh which provides plenty of bandwidth I believe. I have about 14Mb Up |
|
Send message Joined: 9 May 10 Posts: 14 Credit: 3,529,548 RAC: 0 |
And both machines are running spinning disks in raid-0 for storage where boinc directory is stored |
|
Send message Joined: 15 Jun 08 Posts: 2739 Credit: 301,894,252 RAC: 83,684 |
gfiles show that your computers return lots of errors with typical messages like: [pre]2020-11-17 00:42:14 (16056): VM Heartbeat file specified, but missing. 2020-11-17 00:42:14 (16056): VM Heartbeat file specified, but missing file system status. (errno = '2')[/pre] or [pre]2020-11-17 00:55:27 (23652): Guest Log: [ERROR] Enviroment setup script /cvmfs/grid.cern.ch/emi3wn-latest/etc/profile.d/setup-wn-example.sh does not exist.[/pre] The 1st error points out a disk bottleneck due to heavy IO activity. To avoid this - do not start lots of tasks concurrently (may require a self made script). - set up additional BOINC clients and put their working directories on individual disks (to be added). The 2nd error points out network delays. Those delays end up in missing files that should have been refreshed by the CVMFS client or the Frontier client. Depending on the file that is missing other errors follow. Even tasks marked as success and rewarded seem to be not fully successful, e.g.: https://lhcathome.cern.ch/lhcathome/result.php?resultid=289077725 https://lhcathome.cern.ch/lhcathome/result.php?resultid=289029675 It looks like each of those tasks got just 1 subtask and did not manage to get a 2nd one. This also point out network delays. There is no way to get to these machines other than wifi. Wi-fi plays a major role regarding the network delays since the real bandwidth never reaches the nominal bandwidth. In addition it is a shared medium and the real bandwidth is spread among all connected devices. You may at least - connect the 2 computers via 1-Gbit ethernet switch and high quality cables - setup a squid proxy on one of your computers (can then be used by both) Experts from Fermilab recommend to use a local squid if you run more than 10 worker slots - your computers provide 96 (!) worker slots. If a cable connection between your computers and your router is not possible you may think about a pair of powerline adapters to replace the wi-fi. This should improve stability and real bandwidth. If all of that is not possible you need to reduce the number of concurrently running tasks to a value that ensures stability. |
|
Send message Joined: 9 May 10 Posts: 14 Credit: 3,529,548 RAC: 0 |
Thanks for the advice. I will look into this further tomorrow. In the meantime, do you know if port forwarding could help with the networking side of things? The nodes in question are on a separate electrical service than the one that services the gateway so a powerline adapter is not an option either unfortunately. |

©2026 CERN