
Message boards : Theory Application : Theory not utilizing all cores
Message board moderation
Previous · 1 · 2 · 3 · Next
| Author | Message |
|---|---|
 Magic Quantum Mechanic Magic Quantum MechanicSend message Joined: 24 Oct 04 Posts: 1313 Credit: 97,694,594 RAC: 106,766 |
Magic, could you run an 8-core Theory once again on one of your i7-3770's to check it's running 8 jobs within the VM or only max 4? I will try that again as soon as one of them are ready for new work. But I just remembered something I tested here a couple months ago after we started running multi-core Theory here. I was running on these 8-core pc's three X2 tasks and 3 single LHCb at the same time which means in some way I had 9 tasks running on an 8-core (sort of) so it must mean that these multi-core Theory tasks still allowed me to run those 3 LHCb tasks at the same time. I stopped running them that way just because I would have to always start the three X2 Theory tasks first and then the three LHCb tasks. Here is a snapshot I took of this back in the first week of July 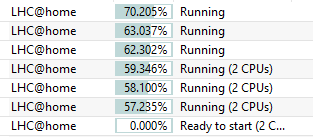 |
|
Send message Joined: 13 Apr 18 Posts: 443 Credit: 8,438,885 RAC: 0 |
@ Luigi R Interesting bash script and graph from you. Your troubles may be just a Linux thing. I have https://lhcathome.cern.ch/lhcathome/show_host_detail.php?hostid=10557960 on Linux (Ubuntu) on which I can test an 8 core Theory. It's showing only 6 cores now because I have HT turned off for an experiment on how HT affects performance on ATLAS native tasks. When current tasks complete I'll set it up for an 8 core Theory and we'll see what the graph from my host looks like. |
|
Send message Joined: 7 Feb 14 Posts: 99 Credit: 5,180,005 RAC: 0 |
Ok, that task was long. It was reported some while ago. I have an almost complete graph. Graph 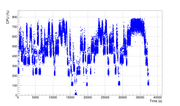 Task https://lhcathome.cern.ch/lhcathome/result.php?resultid=206334370 On night CPU usage was very good. 8 threads were used. @ Luigi R Let us know. ;) |
|
Send message Joined: 14 Jan 10 Posts: 1556 Credit: 10,101,515 RAC: 1,464 |
On night CPU usage was very good. But not all the time. There were several gaps between finish and start of a job. CPU efficiency 4.5 out of 8 available threads. |
|
Send message Joined: 14 Jan 10 Posts: 1556 Credit: 10,101,515 RAC: 1,464 |
I retested the 8-core VM (https://lhcathome.cern.ch/lhcathome/result.php?resultid=206346600) and this time the result was much better. All 8 cores/VM-slots were used. The first 2 jobs were still running before the next 2 have to start after 20 minutes. After the initially setup where the jobs are started pairwise with an interval of about 20 minutes and before the jobs are finishing one after another without using the freed cores, the efficiency of the 3 VBoxHeadless processes was 83.9% Average CPU MHz used now Total CPU cycles 83.90444591 % 22359.82 1.05231269844286E+15 0.000013645 % 0 171140926 0.000009997 % 0 125386186 Average total: 83.904469555044 % Average MHz: 22895.85 Current load: 81.9401390906526 % Also after the finish of a job, a new job started shortly after in that freed slot. E.g: 09:42:16 +0200 2018-09-02 [INFO] New Job Starting in slot1 13:04:17 +0200 2018-09-02 [INFO] Job finished in slot1 with 0. 13:04:42 +0200 2018-09-02 [INFO] New Job Starting in slot1 17:02:37 +0200 2018-09-02 [INFO] Job finished in slot1 with 0. 17:03:00 +0200 2018-09-02 [INFO] New Job Starting in slot1 18:03:57 +0200 2018-09-02 [INFO] Job finished in slot1 with 0. 18:04:25 +0200 2018-09-02 [INFO] New Job Starting in slot1 20:16:31 +0200 2018-09-02 [INFO] Job finished in slot1 with 0. 20:16:56 +0200 2018-09-02 [INFO] New Job Starting in slot1 21:15:26 +0200 2018-09-02 [INFO] Job finished in slot1 with 0. 21:15:40 +0200 2018-09-02 [INFO] New Job Starting in slot1 00:02:27 +0200 2018-09-03 [INFO] Job finished in slot1 with 0. Towards the end CPU-cycles are wasted because of not used cores. 22:16:49 +0200 2018-09-02 [INFO] Job finished in slot5 with 0. 22:34:31 +0200 2018-09-02 [INFO] Job finished in slot4 with 0. 23:36:01 +0200 2018-09-02 [INFO] Job finished in slot2 with 0. 00:00:05 +0200 2018-09-03 [INFO] Job finished in slot8 with 0. 00:02:27 +0200 2018-09-03 [INFO] Job finished in slot1 with 0. 00:05:55 +0200 2018-09-03 [INFO] Job finished in slot6 with 0. 01:32:02 +0200 2018-09-03 [INFO] Job finished in slot7 with 0. 02:06:56 +0200 2018-09-03 [INFO] Job finished in slot3 with 0. |
|
Send message Joined: 15 Jun 08 Posts: 2755 Credit: 304,271,457 RAC: 116,232 |
nk leads to a 4-core Theory VM. The timestamps in your examples also don't match the linked log. https://lhcathome.cern.ch/lhcathome/result.php?resultid=206346600 [pre]2018-09-02 09:32:45 (4976): Setting CPU Count for VM. (4)[/pre] |
|
Send message Joined: 14 Jan 10 Posts: 1556 Credit: 10,101,515 RAC: 1,464 |
The link leads to a 4-core Theory VM. I changed directly after the start the VM-settings to 8 cores and restarted the VM: 2018-09-02 09:33:57 (4976): Stopping VM. 2018-09-02 09:43:05 (2412): Detected: vboxwrapper 26197 2018-09-02 09:43:05 (2412): Detected: BOINC client v7.7 The times from the VM and the host will differ after several hours of runtime. I took the times from the VM-logs and not stderr.txt. As you can see slot 1 up to 8 were used and the used cpu time and elapsed time shows more CPU use than a 4 core can give: Elapsed 16 hours 38 minutes 34 seconds CPU time 4 days 5 hours 2 minutes 15 seconds |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1313 Credit: 97,694,594 RAC: 106,766 |
computezrmle I am starting one of the 8-core tasks on one of my i7-3770's in a couple seconds. . |
|
Send message Joined: 15 Jun 08 Posts: 2755 Credit: 304,271,457 RAC: 116,232 |
Thank you, it's clearer now. I agree 100% with the conclusions. Cycle thefts are: 1. The staggered startup (20 min delay) 2. The job's runtime differences at the end of the WU BTW: Time drifts should not occur as every VM starts it's own NTP service. You may consider to check if your firewall allows traffic from your VMs to external UDP port 123 and back. Faster and more elegant would be to redirect the NTP requests to an already existing time source inside your LAN. Some firewalls/routers provide functions to do those redirects. |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1313 Credit: 97,694,594 RAC: 106,766 |
While I am watching the Log of the 8-core task I started I took a quick snapshot of the 3-core task I already have been running on the pc next to it. These 3 jobs started in 22 minutes 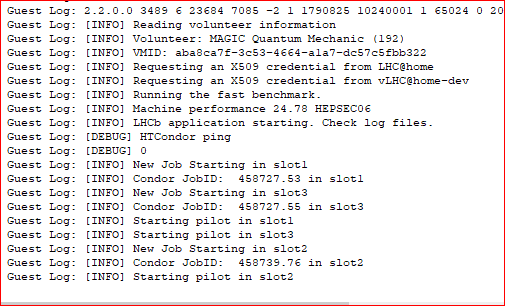 |
|
Send message Joined: 15 Jun 08 Posts: 2755 Credit: 304,271,457 RAC: 116,232 |
It's an LHCb, not a Theory. Would be nice to see the timestamps. Is there a delay between the first 2 and the 3rd? |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1313 Credit: 97,694,594 RAC: 106,766 |
Yes I figured you would know what that was so I just wanted to show you how they are doing while I watch the 8-core here. That LHCb went 1-3-2 slots in 22 minutes. Here is the 8-core after one hour with time. 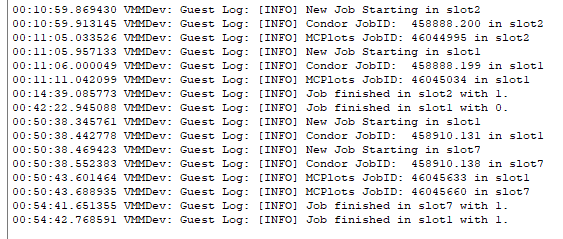 As you can see it was 11 minutes before the first job started (its 2am so I better go fake sleep and I'll check back later Stefan) |
|
Send message Joined: 14 Jan 10 Posts: 1556 Credit: 10,101,515 RAC: 1,464 |
@MAGIC: Interesting is that the 3rd job not started after about 20 minutes, maybe because of the quick finishes of job 1 and 2. It seems that the staggered startup gets confused by that, what I already mentioned before. |
|
Send message Joined: 13 Apr 18 Posts: 443 Credit: 8,438,885 RAC: 0 |
@MAGIC: Note that job 2 finished with 1 (error) rather than 0. If there is a confusion then maybe it's due to Condor pondering the cause of the error and what it should do next. It seems that the staggered startup gets confused by that, what I already mentioned before. But does the confusion cause it to fail to start jobs in all 8 slots? We can't see that from Magic's 1 hour Log excerpt. I have an 8 core VBox Theory running here, https://lhcathome.cern.ch/lhcathome/result.php?resultid=206367015. The Log shows a quick finish of job 2 but it finished with 0 rather than 1. Jobs started in timely fashion in all 8 slots despite the early finish of job 2. You'll see it all in stderr output after task completion. |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1313 Credit: 97,694,594 RAC: 106,766 |
That 8-core task I tried late last night turned out to only run 1 hour 10 min 51 sec and Valid (I saw it this morning) https://lhcathome.cern.ch/lhcathome/result.php?resultid=206368984 I just got home and checking my tasks it has been a strange day here today with my Theory tasks. Many Valids that were also only run just over an hour (2-core multi's) And a page full of the Invalids as usual that are those 27 minute runs ending with the typical...... VM Completion File Detected. VM Completion Message: Condor exited after 985s without running a job. Mixed in with several of the *normal* looking Valids (18 hours) |
|
Send message Joined: 13 Apr 18 Posts: 443 Credit: 8,438,885 RAC: 0 |
ed the 8 core Theory I started, https://lhcathome.cern.ch/lhcathome/forum_index.php. It began with several quick finishes which I don't understand. I've never seen a Theory sub-job finish in 20 minutes so something very strange going on there, maybe those quick finishes aren't the usual pythia/herwig/sherpa jobs, whatever. In spite of those quick finishes the task eventually revved up to a full 8 slots. The disappointing bit is here: [pre]2018-09-03 11:23:42 (2717): Guest Log: [INFO] Job finished in slot2 with 1. 2018-09-03 11:43:37 (2717): Guest Log: [INFO] Job finished in slot5 with 0. 2018-09-03 11:45:02 (2717): Guest Log: [INFO] Job finished in slot7 with 0. 2018-09-03 11:45:07 (2717): Guest Log: [INFO] Job finished in slot4 with 0. 2018-09-03 11:45:56 (2717): Guest Log: [INFO] Job finished in slot1 with 0. 2018-09-03 11:52:56 (2717): Guest Log: [INFO] Job finished in slot6 with 0. 2018-09-03 12:16:14 (2717): Guest Log: [INFO] Job finished in slot8 with 0.[/pre] where slot2 finishes with an error. Soon after every slot except for 3 also finishes and the task drags on for another 5 hours doing next to nothing (probably a useless looping sherpa) until it bumps up against the 18 hour limit at : [pre]2018-09-03 17:24:51 (2717): Removing virtual disk drive from VirtualBox.[/pre] @Luiigi_R I ran your logging script but didn't check its output until the task finished. It seems we have top configured differently. The 9th field in the output from my top is either S, Z, I or R, not %CPU. I should have changed the "awk '{print $9}' " to "awk '{print $10}' ". Oh well. |
|
Send message Joined: 7 Feb 14 Posts: 99 Credit: 5,180,005 RAC: 0 |
@Luiigi_R I'm sorry not to have mentioned that. :( I had had the same problem. Only once I needed (when I tested that script) the 9th field to get things working, usually I set the 10th field. Meanwhile I tried to disable HT, so I have 4 cores now. The best of two tasks is still a disappointing: click. I need further testing. |
|
Send message Joined: 7 Feb 14 Posts: 99 Credit: 5,180,005 RAC: 0 |
@Luiigi_R It looks there is another issue due to window dimension. If your window is small, your process could be:
|
|
MechaToaster Send message Joined: 17 Aug 17 Posts: 15 Credit: 179,253 RAC: 0 |
It's not what I'm looking for. I don't want 8 tasks, I want only 1 tasks that uses 8 cores! im having a similar issue on a ryzen 5 1600x(6 core 12 threads). i had lhc@home configured to use 4 cores per task, i thought it would count threads as cores, but it will not let me run more than 1 theory task on 4 cores at a time, despite having enough RAM available. if i try to run another theory task, it stops and the status updates to "postponed: b". 
|
|
Send message Joined: 5 Mar 06 Posts: 13 Credit: 32,267,134 RAC: 147 |
Hi all, one of my machines has 16c/32t AMD TR1950X and I've also noticed that the new 263.70 multicore app severely under-utilizes the CPU. What's even worse, all tasks I've watched failed at about halfway of the computation. So naturally, I want to try to limit the number of cores as suggested here, but limiting them globally via the web interface seems rather cumbersome to me. In fact, I fine-tune them according to core and memory capacity on each my machine. Isn't there a way to limit them for Theory via app_config.xml file, like it can be done for ATLAS? https://lhcathome.cern.ch/lhcathome/forum_thread.php?id=4161&postid=35921 Anyway, at the moment I've "fixed" it by manually aborting all 263.70 tasks, in hopes that the announced 263.80 version will work better. |

©2026 CERN