
Message boards : Number crunching : Error while computing/too many errors
Message board moderation
| Author | Message |
|---|---|
|
Send message Joined: 26 Jul 05 Posts: 17 Credit: 1,147,143 RAC: 0 |
I am getting many "Error while computing" errors (Too many total results). The pass rate is less than 10%. My system is a Dell Latitude #7240 (4cpu's), with Windows 7, BOINC ver. 7.8.3, and VBox 5.1.3r. The errors occur, even when all other WU's have been "suspended". Any ideas? |
|
Send message Joined: 29 Aug 05 Posts: 1155 Credit: 11,734,925 RAC: 34 |
VirtualBox 5.1.30 is not the latest version; try updating (https://www.virtualbox.org/wiki/Downloads). Make sure you download and install the VirtualBox etensions (http://download.virtualbox.org/virtualbox/5.2.0/Oracle_VM_VirtualBox_Extension_Pack-5.2.0-118431.vbox-extpack), and verify that virtual machines are enabled in your BIOS.  |
|
Send message Joined: 26 Jul 05 Posts: 17 Credit: 1,147,143 RAC: 0 |
Ivan -- Thanks, for the advice. I'll update. |
|
Send message Joined: 26 Jul 05 Posts: 17 Credit: 1,147,143 RAC: 0 |
Ivan -- I've run both LHCb and CMS WU's, with VirtualBox 5.2.0. etc., and still receive the same errors, as before. Shall I keep running them, or await more info. from you? |
|
Send message Joined: 29 Aug 05 Posts: 1155 Credit: 11,734,925 RAC: 34 |
Ivan -- I've run both LHCb and CMS WU's, with VirtualBox 5.2.0. etc., and still receive the same errors, as before. Shall I keep running them, or await more info. from you? I'm afraid you will be getting compute errors with CMS jobs at the moment as the WMAgent failed last night and the job queue drained (so no jobs from condor). Don't run CMS tasks until the job activity graph springs back into life. Sorry 'bout that... |
 adrianxw adrianxwSend message Joined: 29 Sep 04 Posts: 188 Credit: 705,487 RAC: 0 |
I had a small group of "Error while computing" last weekend. An LHCb, a CMS and two Theory Sim's. Wave upon wave of demented avengers march cheerfully out of obscurity into the dream. |
|
Send message Joined: 26 Jul 05 Posts: 17 Credit: 1,147,143 RAC: 0 |
"Error while computing" errors, have resumed, with the latest WU's. CMS and LHCb. |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1305 Credit: 95,839,619 RAC: 20,723 |
"Error while computing" errors, have resumed, with the latest WU's. With you CMS errors I see the first thing on the tasks stderr is Error creating VirtualBox instance You do have the newest version of both VB and Boinc and Oracle says that new version of VB did have a problem with Linux but didn't mention Windows 7 or 10 https://www.virtualbox.org/wiki/Downloads There are several usual problems when starting a new version of VB Did you do the d/l from here with both Boinc and VB or did you d/l VB separately from the Wiki link? Over all the years I have always found upgrading to the new Boinc is best done first and then d/l the new VB from the Wiki link with the Extension Pack THEN reboot before trying to start a new LHC-VB task Another problem is not having a fast enough internet d/l speed to start the tasks and get to the *Credentials* and server connection at Cern and finally the HTCondor ping BEFORE the time is up to do that (10 minutes with CMS and 20 or less with the Theory tasks) Another problem can be checked on your VB Manager Go to the VB Manager and then File/VB Media Manager/ and in that box you may find some vdi's that need to be removed since they can mess up the new tasks trying to get a slot to use. This is what you do not want to see.....and the good and the bad there 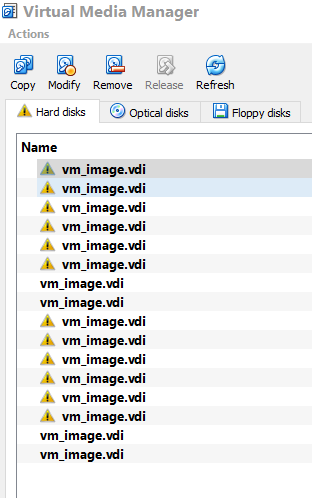 And you can check in that VB Manager for other things such as if that Extension Pack has that Green check mark next to it with that newest version. I tend to watch the VM Console for the tasks as they start so I know for sure they actually got to HTCondor ping so they don't waste time and end up a Computer Error. Once you get used to these tasks you can usually find any problems on your end......now the Cern server and tasks are another story  Volunteer Mad Scientist For Life  unbelievable are you trying to promote linux again? |
|
adrianxw Send message Joined: 29 Sep 04 Posts: 188 Credit: 705,487 RAC: 0 |
>>> The filename or extension is too long. >>> (0xce) - exit code 206 (0xce) I'm seeing a few exits again now. Saw that in the error log. Wave upon wave of demented avengers march cheerfully out of obscurity into the dream. |
|
Send message Joined: 29 Aug 05 Posts: 1155 Credit: 11,734,925 RAC: 34 |
There is an ongoing intervention with some CMS systems, expected to finish in an hour or two. That's probably not causing that particular error though, I wouldn't have thought. |
|
Send message Joined: 26 Jul 05 Posts: 17 Credit: 1,147,143 RAC: 0 |
I think the problem has been resolved. Firstly, I reboot the system, before starting the first LHC WU; whether that has any affect on preventing errors, is not known, but, no errors have followed. Also, as before, I don't have any other WU's running, except the particular LHC one. Any time I need to check personal email, etc., I "pause" the running WU. |
|
Send message Joined: 5 Nov 15 Posts: 144 Credit: 6,301,268 RAC: 0 |
This looked like all of my servers VBox media manager lists and those had to be deleted 1 at a time. No multi-selection. Upgrading to the latest VBox didn't help (but that machine seems to save LHC VM's more quickly on suspend now). A solution discovered, in a fit of frustration, was to suspend all WU's (4 at a time), close BOINC and use a process manager to kill the VBoxSVC.exe service. Once the VBox Manager interface is reopened, the environment is cleaned up. All the broken links to the BOINC data\slot *.vdi files are gone without having to delete them all and without having to reboot the machine. The numbers of broken links to slot vdi's (30, 50, 60 per day) appear to be reduced to a few per day by using Process Hacker and forcing VBoxManager.exe to normal priority from the default idle priority in the assumption it was a time-out issue on a computer where all cores are running at maximum. (Seen crypto wallet's and other apps crash regularly until their priority was raised). This could be a coincidence so I'd like to know if it helps anyone else. |
|
adrianxw Send message Joined: 29 Sep 04 Posts: 188 Credit: 705,487 RAC: 0 |
Picked up 3 recent Error while computing errors again. Wave upon wave of demented avengers march cheerfully out of obscurity into the dream. |
|
Send message Joined: 15 Jun 08 Posts: 2745 Credit: 302,487,461 RAC: 74,438 |
]Picked up 3 recent Error while computing errors again.[/quote] You may examine your logs. https://lhcathome.cern.ch/lhcathome/result.php?resultid=173873928 [pre]2018-01-18 21:20:25 (15796): Guest Log: [DEBUG] nc: connect to vccondor01.cern.ch port 9618 (tcp) timed out: Operation now in progress 2018-01-18 21:20:25 (15796): Guest Log: [DEBUG] 1 2018-01-18 21:20:25 (15796): Guest Log: [ERROR] Could not connect to Condor server on port 9618 2018-01-18 21:20:25 (15796): Guest Log: [INFO] Shutting Down.[/pre] Most likely a problem with the Condor server. https://lhcathome.cern.ch/lhcathome/result.php?resultid=174134896 Most likely: No jobs available at startup time -> VM paused -> Timeout reached after wakeup https://lhcathome.cern.ch/lhcathome/result.php?resultid=174107552 [pre]2018-01-21 00:31:48 (8360): VM state change detected. (old = 'Running', new = 'Paused') 2018-01-21 17:04:04 (8360): VM state change detected. (old = 'Paused', new = 'Running')[/pre] This VM was paused for too long and as it did not finished at least 1 job before it was paused, it was treated as an error. |
|
adrianxw Send message Joined: 29 Sep 04 Posts: 188 Credit: 705,487 RAC: 0 |
>>> Most likely: No jobs available at startup time ... so it trashes an in progress work unit, I doubt that. >>> This VM was paused for too long ... same comment really, if the machine was off or busy or whatever, it trashes a work unit, I doubt that. Wave upon wave of demented avengers march cheerfully out of obscurity into the dream. |
|
Send message Joined: 16 Sep 17 Posts: 100 Credit: 1,618,469 RAC: 0 |
... same comment really, if the machine was off or busy or whatever, it trashes a work unit, I doubt that. Sorry, but that's the way it is. It's all about Condor connections. |
|
adrianxw Send message Joined: 29 Sep 04 Posts: 188 Credit: 705,487 RAC: 0 |
If the server cannot support its own running tasks on remote worker units that represents a serious problem. Not just support, but fail them? Wave upon wave of demented avengers march cheerfully out of obscurity into the dream. |

©2026 CERN