
Message boards : Number crunching : Missing heartbeat file errors
Message board moderation
| Author | Message |
|---|---|
|
Send message Joined: 12 Feb 14 Posts: 72 Credit: 4,639,155 RAC: 0 |
I do not know why my computer has been generating missing heartbeat file errors lately. Tasks take around 10 minutes and then fail due to missing heartbeat files. The things that have changed are my internet connection from a VDSL service which my computer connected to via Wi-Fi that was vulnerable to a microwave oven occasionally wrecking the connection between the VMs and the server to fiber optic gigabit service that my computer connects to via Gigabit Ethernet which is immune to the microwave oven. I do not know how these changes are relevant to the VMs at all. I fear that my computer is therefore damaging the project with its errors and therefore have decided to detach until something changes. I tried to connect to the older vLHC@home project (where I have an account) and still got the same error in order to see if there was something exclusive to the LHC@home project or if it appeared across both projects. |
|
Send message Joined: 14 Jan 10 Posts: 1553 Credit: 10,078,801 RAC: 1,115 |
2 options where the first is the most likely: 1. The VM is not starting to the point where it should write the heartbeat file into the shared folder on the host machine. 2. Your host is too busy with other duties, so that the wrapper can't read the heartbeat timely. Watch VM Console during the first 10 minutes to see what's happening. |
 Magic Quantum Mechanic Magic Quantum MechanicSend message Joined: 24 Oct 04 Posts: 1307 Credit: 96,000,130 RAC: 29,801 |
There is a real good chance that it is your ISP I have this problem quite often with my dsl when I try to start very many during the time of day when my ISP slows me down. I have watched hundreds of my tasks via the VM Console and when the ones don't make it beyond that first 12 minutes they will not get past Starting libvertd daemon [OK] Because after that it is testing the Condor connection and gets the Credentials and the HTCondor ping and when it gets that far your tasks will continue until finished Valid So when I am trying to get new tasks started on several computers and I get that crash and see it not getting to the Condor testing I wait until later when I have a good dsl connection (like right now after midnight here) I usually have the problem during the day when my ISP claims too many people are on line or that I have used more than they figure I should.....so if it is working during the day I go and see if I can get all of the new tasks started. If not I wait until later. After doing this all these years and especially now that we can do as many VB tasks as we want I always try to make sure I still have some running so I can wait until a better time of day or night to start new ones. And since I have just quad cores and a couple 3-cores and just one 8-core I suspend the ones that have been running for hours and start up new ones so that way I can have lots of tasks that already connected to Condor and the Credentials and have as many as 4 tasks running and 4 ready to run and not worried about getting a connection with Cern so when any of the first 4 are finished the other 4 are ready to go and it always works. And Ram is not a very big problem doing this and on my 8-core I only have 8GB Ram but it can run 8 tasks at the same time and have several others ready to go (I tend to make them run 30 minutes before I pause them and restart the other ones that have several hours already) It is easier than it may sound. You can check any of my tasks and you will see I have some of those like you are talking about and that I then just let the others run until I do get this to work. EDIT: I just switched over to another pc to do more of those tasks as I mentioned and wanted to add I do these VB tasks here AND the same over at vLHC at the same time so I do quite a lot of these tasks like this. Edit: Another thing is that the VB is known to have this problem when you try to start several tasks at the same time......such as your 24-cores even though you have plenty of Ram.....and you probably see that you can set your preferences to run as many as 24 tasks....now I don't know how many your run at the same time but it is a good idea to space the tasks out so the VB doesn't cause problems trying to start all of the ones you have at the same time. I have seen Xenons trying to do all of them at the same time and what you usually will get is Computer Errors over and over until the server says that is all you get since you have went beyond your daily total....Valid or Invalid......I used to get those by just letting mine run without watching them get these 12 minute crashes because of my DSL problem and then had to wait as long as 24 hours before the server let me get new tasks. Volunteer Mad Scientist For Life  unbelievable are you trying to promote linux again? |
|
Send message Joined: 2 May 07 Posts: 2298 Credit: 179,562,602 RAC: 30,151 |
Since more than one week becoming no Tasks for CMS or LHC running. Heartbeat Error in all tasks. After 10 or 11 Minutes they close without heartbeat of Condor. 2016-12-18 19:32:52 (4216): VM Heartbeat file specified, but missing. 2016-12-18 19:32:52 (4216): VM Heartbeat file specified, but missing file system status. (errno = '2') 2016-12-18 19:32:52 (4216): Capturing screenshot. ISP is not changed (70MBit down, 40MBit up). ATLASatHome tasks are running well. |
|
Send message Joined: 14 Jan 10 Posts: 1553 Credit: 10,078,801 RAC: 1,115 |
ATLASatHome tasks are running well. ATLAS is not yet working with Condor and credentials, but surely will after consolidation with LHC@home. |
|
Send message Joined: 27 Sep 08 Posts: 941 Credit: 781,970,781 RAC: 81,861 |
I had one of these today generally for me the biggest errors is no ping from Condor. I have a couple of machines that run lots of VM (24) the lowest I run is 8 and I did see some hypervisor errors in older vBox but the seem to have been resolved in the latest versions. I'm interested to see how my new PC with 48 VM's works |
|
Send message Joined: 15 Jun 08 Posts: 2748 Credit: 302,663,200 RAC: 73,377 |
Each CERN VM generates several thousand HTTP requests during the task initialisation phase. CMS nearly 5000, ATLAS nearly 3000. While 20% of those requests are HTTP/1.1, 80% of them are HTTP/1.0. The numbers are typical for my setup and may differ for other users. HTTP/1.1 requests use persistent connections and appear as one (or a few) large filetransfer along the route to CERN. HTTP/1.0 requests instead use a separate TCP connection for every small file that is transferred. In addition the DNS traffic increases (UDP packets) as some of the servers have DNS entrys that are valid for only 2-60 seconds. I wouldn´t be surprised if some of the problems that are reported from high performing users are caused by - home routers that can handle high speed transfers but are overcharged by thousands of concurrent connections - IDS systems along the route that treat the connections as DoS attacks. |
|
Send message Joined: 12 Feb 14 Posts: 72 Credit: 4,639,155 RAC: 0 |
I am using the same ISP, AT&T. My family has switched the connection method to said ISP from U-Verse VDSL to U-Verse GigaPower fiber and shut down the U-Verse overcompressed IPTV service so that no longer competes for throughput. (TV on the antenna is much clearer.) As for ATLAS@home tasks, they still work well on my machine now. |
|
Send message Joined: 12 Feb 14 Posts: 72 Credit: 4,639,155 RAC: 0 |
What do you want me to look for in the VM console? I do not know how to interpret it. |
|
Send message Joined: 12 Feb 14 Posts: 72 Credit: 4,639,155 RAC: 0 |
I am noticing errors with the following error message in my VM consoles: /etc/rc3.d/S99local: line 1: cvmfs/grid.cern.ch/vc/sbin/bootstrap: No such file or directory I am starting to suspect that we might have a run of bad work units with missing files that just coincidentally happened while my Internet service was being replaced. |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1307 Credit: 96,000,130 RAC: 29,801 |
When you watch the task starting up on the VM Console the ones that do not connect to the Condor will not get beyond this and between 11 and 12 minutes will become a Computer Error 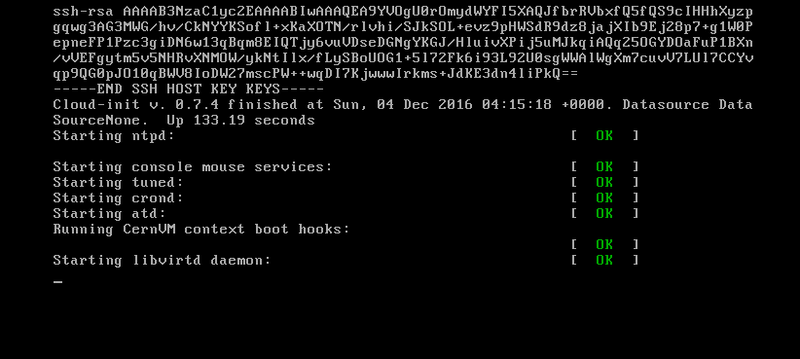 The faster the connection the better but if you watch yours and it goes beyond this on your VM Console it will continue to the next few steps where it connects to the server and then gets the X509 Credentials from the LHC and last but not least it will finish here telling you this task will run all the way to the finish of a Valid task after this HTCondor ping and the last line after that. 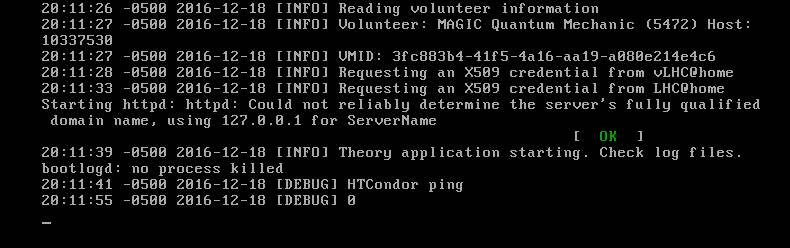 And here is an example of that other thing I do to get around those tasks that never get past the Starting libvertd daemon [OK]  That is on an 8-core with only 8GB ram (Theory tasks take less Ram than a CMS) |
|
Send message Joined: 12 Feb 14 Posts: 72 Credit: 4,639,155 RAC: 0 |
I am getting to the line below as seen in your first screenshot: Starting libvirtd daemon: [ OK ] Just after that, I get the error message below: /etc/rc3.d/S99local: line 1: cvmfs/grid.cern.ch/vc/sbin/bootstrap: No such file or directory I think that the VM is trying to read a file that does not exist or is misnamed either itself or in the program that attempts to read it. This file apparently needs to be read before the VM can attempt to contact Condor. Since it cannot be read, the tasks end in a compute error. |
|
Send message Joined: 12 Feb 14 Posts: 72 Credit: 4,639,155 RAC: 0 |
To clear things up, I am getting messages like below in the VM console for the work units I have tried to run: Starting libvirtd daemon: [ OK ] I think that the VM is trying to read a file that does not exist or is misnamed either itself or in the program that attempts to read it. This file apparently needs to be read before the VM can attempt to contact Condor. Since it cannot be read, the tasks end in a compute error. |
|
Send message Joined: 28 Sep 04 Posts: 804 Credit: 65,696,384 RAC: 24,665 |
I am getting the exact same error message. I am only trying to run one vbox task at the time (Theory). The net connection is exellent (Speedtest gave 168 Mbps down and 71 Mbps up). The latest task is here: https://lhcathome.cern.ch/lhcathome/result.php?resultid=110155646 I took a screen capture of the virtualbox monitor window. Hope I didn't cause it to exit as the stderr has now hypervisor system log at the end which I haven't noticed on previous failed tasks. 
|
|
Send message Joined: 29 Aug 05 Posts: 1158 Credit: 11,749,505 RAC: 1,380 |
To clear things up, I am getting messages like below in the VM console for the work units I have tried to run: The file /cvmfs/grid.cern.ch/vc/sbin/bootstrap exists; curious that you seem to be missing the leading slash. It does take a while to access /cvmfs files the first time, I wonder if something is slowing your net access enough that it times out. I'll mail Laurence about this.  |
|
Send message Joined: 28 Sep 04 Posts: 804 Credit: 65,696,384 RAC: 24,665 |
My error actually shows the first lash in front of cvmfs. Otherwise the error seems identical.
|
|
Send message Joined: 12 Feb 14 Posts: 72 Credit: 4,639,155 RAC: 0 |
You are right. I had transcribed the error wrong. It is as below: Starting libvirtd daemon: [ OK ] |
|
Send message Joined: 29 Aug 05 Posts: 1158 Credit: 11,749,505 RAC: 1,380 |
OK, so it's a CVMFS initialisation problem of some kind. |
|
Send message Joined: 12 Feb 14 Posts: 72 Credit: 4,639,155 RAC: 0 |
I just tried to ping grid.cern.ch, and all of the pings failed. Is there a firewall in between my computer and that server dropping pings? Is grid.cern.ch down? DNS was able to resolve that server's IP address as 198.105.244.130. I am trying to see if there is a network issue between my computer and the server. |
|
Send message Joined: 29 Aug 05 Posts: 1158 Credit: 11,749,505 RAC: 1,380 |
I just tried to ping grid.cern.ch, and all of the pings failed. Is there a firewall in between my computer and that server dropping pings? Is grid.cern.ch down? DNS was able to resolve that server's IP address as 198.105.244.130. I am trying to see if there is a network issue between my computer and the server. I'm not sure how you came up with that address -- it's in a block allocated to Search Guide Inc in Boulder, CO. Caution: simplified and possibly erroneous explanation follows... grid.cern.ch in this instance does not refer (directly) to a host, but to a repository within CVMFS (CERN VM file system). /cvmfs is a read-only cached file system, which uses http transfers to maintain local copies of files at various hosts or repositories. So, when you ask for access to a file within /cvmfs/grid.cern.ch/ the cvmfs software checks to see if it has a local copy. If so, it checks with a preset squid proxy server to see if it has the latest version, and loads the newer version if necessary via the proxy. Obviously, if it doesn't have the file it asks for the latest copy anyway. Thus /cvmfs gradually builds up into a local cache of the repositories that have been installed within it. In the case of our VMs those are cms.cern.ch, grid.cern.ch, cvmfs-config.cern.ch and cms-ib.cern.ch. What is probably happening is that something is slowing the response for all the handshaking that goes on between your VM, the proxy, and the repository, so that the request for the file times out on some link and cvmfs then thinks the file does not exist. If you want to try to test the link manually, you need to use lhchomeproxy.cern.ch on port 3125. |

©2026 CERN