|
61)
Message boards :
Number crunching :
Download errors
(Message 26830)
Posted 4 Oct 2014 by Richard Haselgrove Post: Out of all that lot, I see four instances of 04.10.2014 09:27:29 | LHC@home 1.0 | [http] [ID#322] Received header from server: HTTP/1.1 404 Not Found As Eric told us, the files have been deleted from the server, so there is nothing to download. It's a slightly clunky way of getting rid of the faulty tasks, but with no download and no computing time, very few resources are wasted. The tasks will be issued 5 times each (until the maximum error count is reached), and then we'll be rid of them. It is possible to cancel tasks on the server so they don't have to go through that error cycle, but I'm afraid I can't give Eric step-by-step instructions how to do it: it might be something to look into for the future, just in case one of the remote job submitters puts their foot in it again sometime. |
|
62)
Message boards :
Number crunching :
Tasks exceeding disk limit
(Message 26791)
Posted 3 Oct 2014 by Richard Haselgrove Post: I change disk value to 400000000 and restart. You would probably need to make that change in client_state.xml rather than init_data.xml Very much at your own risk. |
|
63)
Message boards :
Number crunching :
Out of disk space
(Message 26781)
Posted 3 Oct 2014 by Richard Haselgrove Post: No, it's nothing to do with the amount of disk space available in total. It's a limit set by the project, using a facility provided by BOINC and designed to cut off rogue applications before a single task runs rampant and uses all the space allocated to BOINC (all tasks, all projects) on your machine. Have a look at the explanation I posted in Tasks exceeding disk limit. It would probably help Eric if we could consolidate all the different reports of this same error (with slightly different wording each time) into a single discussion thread. |
|
64)
Message boards :
Number crunching :
Tasks exceeding disk limit
(Message 26776)
Posted 3 Oct 2014 by Richard Haselgrove Post: The w-b3_ tasks are sent by the server with this line in the workunit definition: <rsc_disk_bound> 200000000 - decimal 200 MB. While running, working files fort.61 thru fort.90 seem to start growing exponentially: this screengrab was taken at about 50% progress. 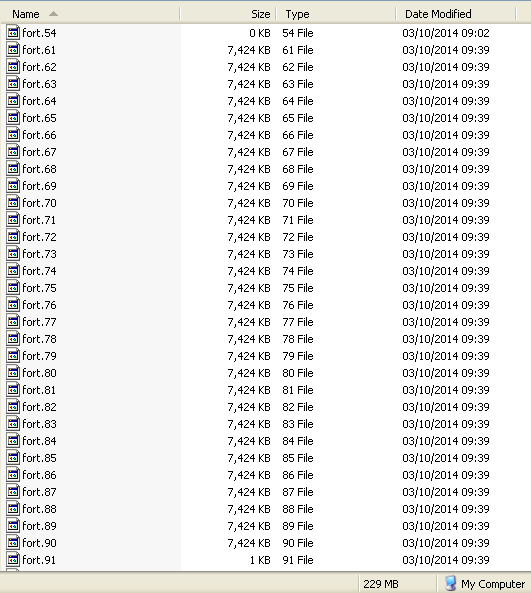 With a disk usage of 229 MB already for those 30 files, BOINC should have aborted the task already - and did so shortly afterwards. |
|
65)
Message boards :
News :
DOWNLOAD ERRORS
(Message 26696)
Posted 19 Jul 2014 by Richard Haselgrove Post: I just found one created a little earlier than all the rest: WU 18788924. One user downloaded it successfully, but all the others failed. The second volunteer on that job - host 9649253 seems to be having great difficulty attaching to the project and downloading the sixtrack executable, but that's a different issue. |
|
66)
Message boards :
News :
DOWNLOAD ERRORS
(Message 26691)
Posted 18 Jul 2014 by Richard Haselgrove Post: I noticed a few of these during the course of today - a very small, sporadic, problem, with the majority of jobs downloading just fine. Here's a selection from one of my hosts: Error tasks for host 9924593 They all failed with #define ERR_HTTP_PERMANENT -224
// represents HTTP 404 or 416 errorand every wingmate (validation partner) also failed to download them: that suggests that the problem is at the server end, with the files either missing or inaccessible to the download server. All the workunits that I checked were created around midday on Saturday 5 July. |
|
67)
Message boards :
Number crunching :
Host messing up tons of results
(Message 26674)
Posted 16 Jul 2014 by Richard Haselgrove Post: You can fix that Eric if you change the settings that we talked about in the other thread, accelerate re-tries I think it was called? And as I said in that other thread - message 26567 - I don't think that accelerating retries would help bring additional tasks forward from the end of the queue (that's where they go), but it would help to make sure they're dealt with quickly and effectively when we do reach them. At least the B1 injection run seems to have a low average runtime, so the queue is shrinking rapidly. |
|
68)
Message boards :
Number crunching :
'Uploading' but not in transfers list
(Message 26635)
Posted 8 Jul 2014 by Richard Haselgrove Post: I have another work unit stuck at my end as "Uploading" but marked as "In progress" by the LHC@home server. Assuming you're running the BOINC v7.2.7 client, as well as managing it with the v7.2.7 Manager, that's a really old version, and early in the development cycle for v7.2 - I wouldn't be surprised if it still had a load of bugs left in. You would perhaps be better off upgrading both components to v7.2.42 - the current 'recommended' - but I know some Linux distros were slow to update their repositories. |
|
69)
Message boards :
Number crunching :
Long Running Tasks
(Message 26606)
Posted 25 Jun 2014 by Richard Haselgrove Post: Good; but I am bit worried about "deadline" but maybe OK. It looks as if you have a <report_grace_period> or <grace_period_hours> set in your project configuration file. |
|
70)
Message boards :
Number crunching :
WU % progress stuck
(Message 26583)
Posted 29 May 2014 by Richard Haselgrove Post: Cases where the project science application fails to make any progress, but appears to be active enough for BOINC to think it's still running, have been reported from pretty much every BOINC project for as long as I've been running it. I only notice the Windows reports, and I have a subjective perception that it happens more often on machines with AMD processors, but apart from that nobody seems to have any clue why it happens, or to have been bothered to look. It's relatively rare. My personal suspicion is that any cause, or cure, would be found in the BOINC API (Application Programming Interface) - a library supplied by the BOINC developers to projects, to support common standards for information and control messages between the BOINC client and the science apps. Unfortunately, this is cinderella programming, which it's hard to find anybody interested in - it's neither "sexy science" nor "groovy graphics". If any professional-grade Windows programmer, with modern systems-engineering knowledge of the multi-threaded Windows kernel, were to grab the API by the scruff of its neck and shake it into shape, we'd all be grateful. |
|
71)
Message boards :
Number crunching :
Stuck validation inconclusive
(Message 26567)
Posted 26 May 2014 by Richard Haselgrove Post: I think there is a server setting to put re-tries 1st in the queue. Richard might know. I don't think there's a queue-order setting: my guess is that queue-ordering is primarily governed by primary-key indexing on ResultID - there's not a lot you can do about that. There is a selection of controls which might help to ensure that once the resends at the end of the queue finally reach the front and start getting issued, they spend as little extra time 'in the wild' as possible. Project Options - Accelerating retries That includes sending the resend tasks to hosts with (historically) a fast turnround time - the meaning of 'fast' being configurable - and also reducing the deadline for return. |
|
72)
Message boards :
News :
Three Problems, 22nd May.
(Message 26517)
Posted 22 May 2014 by Richard Haselgrove Post: 1) is certainly a BOINC back-end problem, not the fault of either your application or our clients. Outliers would be good: the other steps you've taken already (provided you keep rsc_fpops_est friendly) should keep it under control for now. Just remember that it goes back to square one with each new version you release. I'm going to write to the dev list with some lessons learned (not least, the lack of server documentation). 2) I don't know either, so I'll be interested to hear what answers you get. 3) I hope you will (or maybe you could get a student or intern to) write a private PM to the worst offenders, politely saying "Please clean your machine up, or take your cycles elsewhere" - or words to that effect. And if that fails, there is a facility for blacklisting a rogue host. CPDN use that combination of procedures (carrot and stick) to some good effect. |
|
73)
Message boards :
Number crunching :
Invalid tasks
(Message 26486)
Posted 18 May 2014 by Richard Haselgrove Post: Your Linux server is fine. With an APR of 6.1685501327024 for the current application, its statistics haven't been purturbed by short-running 'chaotic' tasks, and you run no danger of 'EXIT_TIME_LIMIT_EXCEEDED'. For your windows machine, I'd never suggest running tasks otherwise than the programmers intended. But the programmers intended the tasks to run to completion, and not to be prematurely terminated. You could have a look at your list of Tasks in progress for host 10308609, and selectively cull the jobs which are at risk of failure. Click on the number in the 'Workunit' column for each task in turn. The top one, WU 17293121 was completed by your wingmate in under three minutes - that's a keeper, it's safe to run. Towards the bottom of page 2 is WU 17279782: that one took 8 hours - too long for you with the server in its current state. I'd abort it and let someone else have a go. And so on down the list. When your wingmate hasn't reported yet, suspend the task and have another look tomorrow. |
|
74)
Message boards :
Number crunching :
Invalid tasks
(Message 26483)
Posted 18 May 2014 by Richard Haselgrove Post: Should I cancel all the WUs I downloaded, or.....just suspend the project? Up to you. As things stand, any task which runs longer than three hours on your machine will be killed: you can cure that (gradually) by running shorter tasks, but catch-22 says that you can't know which tasks are going to be short (that's what the project is here to discover) - except perhaps by waiting until your 'wingmate' has completed and reported their copy of the task. But that's hard work. I see you've run many BOINC projects, for many years. How much have you learned about how it works under the hood? Does the phrase "edit client_state.xml" fill you with dread? There are ways of solving this problem locally, but they require knowledge and care. If you know enough about editing client_state to be worried by it, then you're probably in the right place to learn some more: but if you've never come across it before, then I think I'd advise against. |
|
75)
Message boards :
Number crunching :
Invalid tasks
(Message 26481)
Posted 18 May 2014 by Richard Haselgrove Post: This is the 'EXIT_TIME_LIMIT_EXCEEDED' error we were discussing yesterday in the thread of the same name. Host 10308609 has an APR of 178.17200653414 for the 64-bit PNI app, version 451.07 (production). Qax, this is a problem on the server, not on your computer. Eric is aware of it. Don't adjust your settings, but you might prefer to concentrate on another project for a few hours. Eric, we probably need that high rsc_fpops_bound multiplier on the production tasks for a while at least. Do we have outlier detection in the current validator? If not, we need it, or this will keep happening. Once the server has been 'vaccinated' against outliers, you could try running 'reset credit statistics for this application' from Estimating job resource requirements. |
|
76)
Message boards :
Number crunching :
Invalid tasks
(Message 26468)
Posted 17 May 2014 by Richard Haselgrove Post: Unusual : All boxes ran windows and for some reason mine always picked SSE3, where the others picked PNI ... but otoh., I patched my clients to report SSE3 (5.10.28 didn't know that extension yet) Usual. 'SSE3' and 'Prescott New Instructions' are synonyms, and the applications are identical. |
|
77)
Message boards :
Number crunching :
197 (0xc5) EXIT_TIME_LIMIT_EXCEEDED
(Message 26467)
Posted 17 May 2014 by Richard Haselgrove Post: Richard, you know BOINC very very well! Thanks both. I simply spend too long watching BOINC at work - I need to get out more! Seems like adjusting the rsc_fpops_est for each app version isn't too bad an option assuming you know what to set it too? It's not the app_version which determines rsc_fpops_est, but the varying number of collider orbits - the "max work done", max turns multipled by number of particles, as described by Eric. Provided rsc_fpops_est is proportional to that, we're in business. I mentioned the 'shortened test work' problem because of recent experience at another project - a developer sent out 1-minute test jobs, while leaving rsc_fpops_est at their standard value appropriate for 10-hour jobs. Ooops, chaos (in the non-mathematical sense of the word). It would be helpful if the early tasks sent out after a version change could, as far as possible, lie some way south of the chaos boundary: not only each individual host record, but the project as a whole, maintains averages for speed and runtime, and these can and will be poisoned if there are too many early exits in the initial stages. After that, BOINC does in fact provide a feature which we can use. I discovered this morning that it's completely undocumented, but we did actually touch on it here a couple of years ago: message 24418 If you can arrange for the validator to set the 'runtime_outlier' flag for tasks where a significant proportion of the simulated particles fail to complete the expected number of turns, BOINC won't use those values to update the averages. That should help to keep the server estimates stable. The source code link I provided last time no longer works, but you can read David's explanation in http://boinc.berkeley.edu/gitweb/?p=boinc-v2.git;a=commit;h=e49f9459080b488f85fbcf8cdad6db9672416cf8 |
|
78)
Message boards :
Number crunching :
197 (0xc5) EXIT_TIME_LIMIT_EXCEEDED
(Message 26461)
Posted 16 May 2014 by Richard Haselgrove Post: Your 3770T is host 9934731. The application details for that host - newest at bottom - show the effect I was talking about: SixTrack 451.07 windows_intelx86 (pni) Average processing rate 98.413580511401 That's a single core running with SSE3 optimisation at near enough 100 GigaFlops. Or so BOINC thinks. Since this is more than 30 times the Whetstone benchmark of 3037.96 million ops/sec, the rsc_fpops_bound is extremely likely to kick in. Unfortunately, since this is clearly (ha!) the most efficient application version for your host, the server will preferentially send tasks tagged for this app_version - and they will continue to fail. I don't think there's anything a volunteer can do, client_side, to escape from this catch-22: the quickest way out is to declare yourself a cheater by fiddling with rpc_seqno, and thus get a new HostID assigned. And hope that you get some moderate runtime tasks allocated in the early stages, so you seed APR with some sane values. If, by the luck of the draw, you happen to be assigned some short, but not excessively short, tasks, APR will be adjusted downwards on each successful completion, and you might eventually dig yourself out of the trap - but that's not guaranteed. The highest APR I can find for any of your 3770S hosts is 76.58 for host 9961528. You must have just scraped under the wire with that one - a more serendipitous mix of WUs. |
|
79)
Message boards :
Number crunching :
197 (0xc5) EXIT_TIME_LIMIT_EXCEEDED
(Message 26459)
Posted 16 May 2014 by Richard Haselgrove Post: I think there are probably three elements of your recent testing which are conspiring to confuse BOINC's scheduling. 1) Deployment of new application versions 2) Artificially shortened test tasks 3) Non-deterministic runtimes Under the Runtime Estimation process associated with Credit New, each new app_version starts with a blank set of estimates. If the early results for a particular host all have a short runtime (either because the workunit has been shortened without a corresponding reduction in rsc_fpops_est, or because the simulation hits the wall), the server accepts - without sanity checking, so far as I can tell - that the host is extraordinarily fast: this is visible as the 'APR' (Average Processing Rate) on the Application Details page for the host. Once an initial baseline has been established (after 10 'completed' tasks), the APR is used to estimate the runtime of all future tasks. If the host subsequently runs perfectly 'normal' tasks - correct rsc_fpops_est, and no early exit - the runtime is likely to exceed the rsc_fpops_bound at normal processing speeds. The sledgehammer kludge is to increase rsc_fpops_bound for all workunits to 100x or even 1000x rsc_fpops_est, instead of the default 10x. This, of course, negates the purpose of rsc_fpops_bound, which is to catch and abort looping applications. But that's probably the lesser problem here. The more complicated solution is to remember to adjust rsc_fpops_est for each different class of WUs - most critically, shortened test WUs (and doing urgent, repeated, tests is of course exactly when you least want to be fiddling with that. C'est la vie) If you have any way of 'seeding' new application versions with tasks that don't crash out early, that would also help - but that rather defeats the purpose of the project. |
|
80)
Message boards :
Number crunching :
sixtracktest v450.09 (sse3) windows x86 : CreateProcess() failed
(Message 26361)
Posted 22 Apr 2014 by Richard Haselgrove Post: A similar set of missing dependencies turned up in an Einstein application recently. Bernd's response also implicated static linking: The problem seems to be that the libstdc++-6.dll is not linked statically into the App. The version of the MinGW compiler that I used for the first time apparently requires an addional option for this (-static-libstdc++). |
Previous 20 · Next 20

©2024 CERN