
Message boards : Theory Application : Errors
Message board moderation
| Author | Message |
|---|---|
 Magic Quantum Mechanic Magic Quantum MechanicSend message Joined: 24 Oct 04 Posts: 1311 Credit: 97,554,525 RAC: 104,709 |
https://lhcathome.cern.ch/lhcathome/results.php?hostid=10453436 I had 5 tasks suspended for a couple hours and just checked and they all decided to become Errors. Volunteer Mad Scientist For Life  unbelievable are you trying to promote linux again? |
|
Send message Joined: 14 Jan 10 Posts: 1556 Credit: 10,100,748 RAC: 1,717 |
https://lhcathome.cern.ch/lhcathome/results.php?hostid=10453436 That can and will happen when you suspend several BOINC VM's at the same time with 'Leave applications in memory' (LAIM) not selected (or BOINC-client is quitted). The wrappers have to write the VM-states to disk (take a snapshot) and BOINC expects this is done within 60 seconds. When not the VM will not be saved and the VM will get the 'stopped' state. Sometimes when you resume the task, the VM will reboot and get a new job, but often the task will end into an error. Advice: When enough memory keep the tasks in memory (LAIM on) or with LAIM off (or BOINC quit) suspend the tasks one after another and watch with VirtualBox Manager if the VM is properly saved. |
|
Send message Joined: 30 Jan 17 Posts: 7 Credit: 132,213 RAC: 0 |
Could you please point to one of the results that failed that way? I can't seem to be able to find one that fits the description. All I can see is network errors (206). |
|
Send message Joined: 14 Jan 10 Posts: 1556 Credit: 10,100,748 RAC: 1,717 |
Could you please point to one of the results that failed that way? I can't seem to be able to find one that fits the description. All I can see is network errors (206). Found in one of the results: 2017-07-13 02:03:45 (8116): VM state change detected. (old = 'Running', new = 'Paused') 2017-07-13 02:04:00 (8116): Stopping VM. 2017-07-13 02:04:00 (8116): Error in stop VM for VM: -108 Command: VBoxManage -q controlvm "boinc_f8ca21b84910800a" savestate Output: 2017-07-13 02:04:00 (8116): VM did not stop when requested. 2017-07-13 02:04:00 (8116): VM was NOT successfully terminated. After the task was resumed the VM rebooted (not restored), had network connections, but could not ping to HTCondor for whatever reason. |
|
Send message Joined: 2 May 07 Posts: 2304 Credit: 179,727,092 RAC: 20,376 |
Magic is....sleeping at the moment ;-) https://lhcathome.cern.ch/lhcathome/result.php?resultid=150655711 1:0 for you Crystal |
|
Send message Joined: 30 Jan 17 Posts: 7 Credit: 132,213 RAC: 0 |
From what I can tell these were separate problems. The machine was not powered off with the savestate command and then defaulted to the poweroff command. But under normal circumstances, upon restarting, it should get the same jobs and start again. The fatal error here was the network one. The powering off merely triggered it. We can monitor the behaviour after following Crystal Pellet's advices and act accordingly. |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1311 Credit: 97,554,525 RAC: 104,709 |
All of mine are set in the Boinc Manager to leave non-GPU tasks in memory while suspended. I suspended those 5 tasks and then started some other task to run and did not reboot. You can see the 5 tasks since they are all errors at the exact same time. I do this all the time with 3 particular 8-core computers (and they are all like that right now) I normally wouldn't care but if they have been running for almost 16 hours and then crash like that........well I am not a fan of wasting time and money and I have been doing this for a long time. And maeax was right.....I am at PDT and I tend to try going to sleep at 4am and don't get back on to check things until around noon PDT Today I have lots of LHC and vLHC-dev tasks suspended so I can run these test tasks and haven't lost anything......(well other than electricity and GB's of internet speed via satellite) Volunteer Mad Scientist For Life unbelievable are you trying to promote linux again? |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1311 Credit: 97,554,525 RAC: 104,709 |
https://lhcathome.cern.ch/lhcathome/result.php?resultid=152070929 Here we go again....several more today here (no problems at vLHC-dev) Guest Log: [DEBUG] DC_NOP failed! Guest Log: AUTHENTICATE:1003:Failed to authenticate with any method Guest Log: AUTHENTICATE:1004:Failed to authenticate using GSI Guest Log: GSI:5004:Failed to authenticate. Globus is reporting error (655360:17) Guest Log: 07/24/17 22:43:34 recognized DC_NOP as command name, using command 60011. Guest Log: 07/24/17 22:43:46 Condor GSI authentication failure Guest Log: GSS Major Status: Authentication Failed Guest Log: GSS Minor Status Error Chain: Guest Log: globus_gss_assist: Error during context initialization Guest Log: globus_gsi_callback_module: Could not verify credential Guest Log: globus_gsi_callback_module: Could not verify credential Guest Log: globus_gsi_callback_module: Invalid CRL: The available CRL has expired Guest Log: 07/24/17 22:43:48 SECMAN: required authentication with local collector failed, so aborting command DC_SEC_QUERY. Guest Log: [ERROR] Could not ping HTCondor. Guest Log: [INFO] Shutting Down. Volunteer Mad Scientist For Life unbelievable are you trying to promote linux again? |
|
Ben Segal Send message Joined: 1 Sep 04 Posts: 143 Credit: 2,579 RAC: 0 |
Hi Magic, Laurence is aware of this and is looking into things. All the best, Ben |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1311 Credit: 97,554,525 RAC: 104,709 |
Hi Magic, Laurence is aware of this and is looking into things. Thanks Ben....long time no see  I had some luck today and went Valid 10 - 1 (now if we could get something done with the vLHC-dev server) -Samson Volunteer Mad Scientist For Life unbelievable are you trying to promote linux again? |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1311 Credit: 97,554,525 RAC: 104,709 |
VM Heartbeat file specified, but missing. 2017-08-18 14:58:34 (3032): VM Heartbeat file specified, but missing file system status. (errno = '2') I wasn't surprised when CMS did this but I can't trust the Theory tasks either. Still can not trust these tasks to just start running so I don't have to stare at 9 computers all day to make sure these tasks start up and not get this heartbeat or credential problems so I end up sitting here watching each task for 20 minutes to make sure they start running. This computers has 4 tasks running but since it is an 8-core with 24GB memory I always run 8 tasks here unless this happens. Makes no sense that these at times can not start running in less than 20 minutes getting the credentials and all the port connections and HTCondor ping Over and over I have to check and make sure they do all of that and THEN I can just let them run to completion and start all over with a new batch. But then over 7 years of running this Oracle VB I am never surprised when one of the problems happen or when they have another update/fix Not that I want my power bill even higher but I never have to worry about the Einstein GPU tasks running Valid OR having to run with the Ethernet plugged in 24/7 (and of course can run hundreds of SixTracks without having to have the Ethernet plugged in until they are ready to send back) Still sitting here trying to get the other 4 tasks started on this pc as I am typing and task #5 just passed 16 minutes and still sitting there on page one of the VM Console Sure wish tasks that I already have started running without all these pre-task OK's I already paid hundreds to get a faster satellite internet connection that always runs between 3MBps-50MBps and that should be more than enough. https://tinyurl.com/PayNoAttentionToTheManBehindTh Volunteer Mad Scientist For Life unbelievable are you trying to promote linux again? |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1311 Credit: 97,554,525 RAC: 104,709 |
Todays example (only one I will try since I don't need to stack up a long list of these) https://lhcathome.cern.ch/lhcathome/result.php?resultid=153836785 The actual reason is Oracle VB demands higher internet speed and the 44 tasks I do have running had to be done after 2am when I had 45Mbps instead of 850Kbps - 1Mbps I have right now. So even after 20 minutes they still do not make it to page 2 of the VM Console 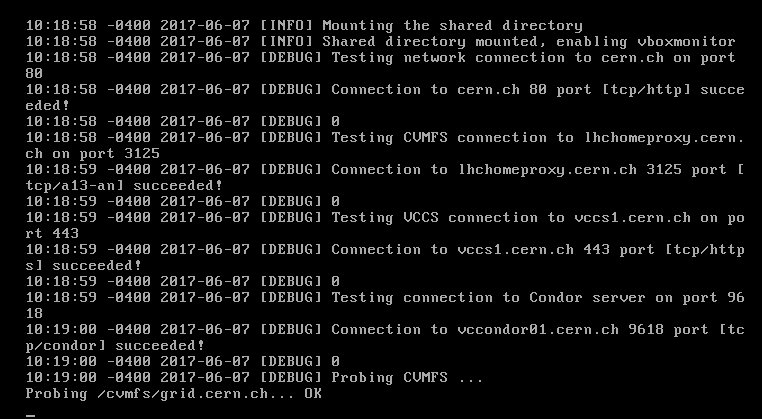 Volunteer Mad Scientist For Life unbelievable are you trying to promote linux again? |

©2026 CERN