
Message boards : Theory Application : Tests of Theory app on LHC@home
Message board moderation
| Author | Message |
|---|---|
 Nils NilsSend message Joined: 15 Jul 05 Posts: 254 Credit: 6,001,083 RAC: 0 |
The Theory simulations application, that has been running successfully for a few years on the Test4Theory/Virtual LHC@home project, will soon be available on this project. This application requires Virtual Box as documented on: http://lhcathome.web.cern.ch/faq. For the moment, we are only generating a few test tasks for test purposes to validate the chain of jobs. More information will follow later. |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1311 Credit: 97,555,835 RAC: 104,823 |
So far on the one host I started these on it has been running like it should so I have 4 complete and Valids Funny thing but I decided to try them on another quad-core I have and instead of just getting 4 new tasks the server decided to give me 30 It is a 30 day due date so I will try to finish them all since I have a free core since over at vLHC there is a new problem that just started. http://lhcathomeclassic.cern.ch/sixtrack/results.php?hostid=10337530 Volunteer Mad Scientist For Life  unbelievable are you trying to promote linux again? |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1311 Credit: 97,555,835 RAC: 104,823 |
Well Nils it looks like we might need to have the Max # jobs setting in the preferences here like we have at vLHC. The first batch I got on the 8-core was just 8 tasks as I expected here and I just manually suspended the ones I didn't want running. But tonight I decided to run some on 3 other quad-cores I have and the problem was I got 72 tasks total for those 3 computers. And since they are quad cores that also are running GPU tasks I need to have one free core and with all these it would try to get these VB tasks to run on all 4 cores and then have all the rest of these waiting to run. We didn't even get as far as running 2 tasks at vLHC until the 5th year and we just started being able to run up to 5+ at a time if we have more cores like a Xenon So it would be nice to set the Max # jobs at 3 or less here. Since my 6 pc's are here at home and I have been doing these VB tasks 24/7 for 6 years I will just suspend all of the ones that aren't running manually and just start them up after the running tasks are finished. But the main thing is they are ALL running and so far no VB problems. (they are taking from 12hrs 45mins to 16hrs 30mins each so far) Volunteer Mad Scientist For Life unbelievable are you trying to promote linux again? |
|
Send message Joined: 14 Jan 10 Posts: 1556 Credit: 10,100,748 RAC: 1,717 |
But tonight I decided to run some on 3 other quad-cores I have and the problem was I got 72 tasks total for those 3 computers. When you've set 'No limit' you will get as many tasks as needed to fill your requested days of work for the buffer in your local BOINC Manager preferences. I don't think it's a good idea to lower 'No limit' otherwise. You can lower your buffer in the project preferences to e.g. 8 and/or lower locally your cache buffer. AFAIK LHC@home (incl. vLHC and LHC-dev) is the only project with this great ability (except WCG CEP's). |
|
Send message Joined: 23 Jun 14 Posts: 1 Credit: 6,552,421 RAC: 0 |
Seems to overflow any cache buffer settings as well. Only running LHC on one host at the moment with my cache set to be "Store at least" = two days with "Store up to an additional" = 1 day I presently have 60 WUs downloaded with an estimated time of fractionally over 18 hours each (which is correct) That's 5.6 days worth for each of my eight cores. Where can I find the project buffer limit setting? |
|
Send message Joined: 14 Jan 10 Posts: 1556 Credit: 10,100,748 RAC: 1,717 |
Where can I find the project buffer limit setting? https://lhcathome.cern.ch/lhcathome/prefs.php?subset=project Remark: Probably you'll only see it when you've attached with the new https-URL -> https://lhcathome.cern.ch/lhcathome 2nd remark: So far 172 hosts did 11,146 valid Theory jobs (no BOINC-tasks). |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1311 Credit: 97,555,835 RAC: 104,823 |
But tonight I decided to run some on 3 other quad-cores I have and the problem was I got 72 tasks total for those 3 computers. LMAO.......well last night while looking at my preferences here I still had the OLD version........now when I check again it now has the new version with that "No Limit" setting. And I didn't do any URL changes since......well I have been here since 2004 so I tend to know what I am doing. So NOW I can use those settings .........of course I still have to do the 80 I have since I'm not going to reset the project. I still had this even today just before I made my post that I just edited here. (I actually have that old version page up right now) 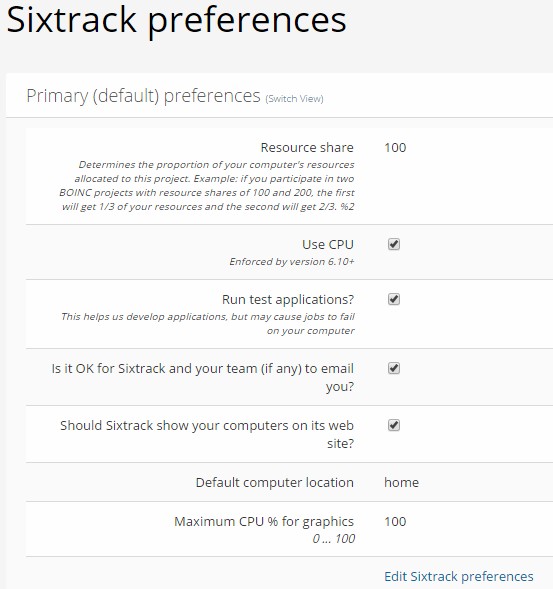 BUT with the new version with that long list of applications I got to go and get rid of all of them except the Theory VB ones (7 Valids so far) |
|
Send message Joined: 14 Jan 10 Posts: 1556 Credit: 10,100,748 RAC: 1,717 |
Hello Samson, It was said that the default setting would be 'Sixtrack' and all other applications not selected, but maybe you had If no work for selected applications is available, accept work from other applications? ticked in your preferences (or in the school, work or home prefs) and since Sixtrack had no jobs, you got Theory's even when not visible in your prefs. |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1311 Credit: 97,555,835 RAC: 104,823 |
I have it working now. I have these 6 computers that I was only using here once in a while pre-VB just so I could use the message boards and at times posted things for Eric McIntosh when he couldn't post here. Well on this one I just went to the Boinc Manager had asked for work while I was over at vLHC.......well it still had the older LHC and since the server doesn't change that URL similar to wrappers over the years it just grabbed all the Theory VB here (glad I didn't get 100 SSE or the many other apps) So after doing the max set here for 3 I went to that pc and since it was doing the last 2 it had I asked for more and it gave me 18 tasks and of course tried starting 8 of them all at once and that sure will not work on a 8-core with only 8GB ram. It froze up and I had to shut it down and reboot and remove that version of LHC so of course it abandoned those 18 and the two it was already running (and I had vLHC X4 running too) So now it is like it should be getting just 2 tasks and I even got lucky and for once the .vdi d/led at 225K instead of the usual 20K and is back up and running 2 VB here and vLHC X4 (if I add another ram stick I could most likely run X3 VB here and X4 vLHC at the same time) and leave just one free core. Ok back to it.............(sheesh how many times do I have to edit my typing) Volunteer Mad Scientist For Life unbelievable are you trying to promote linux again? |
|
Send message Joined: 9 Jan 15 Posts: 151 Credit: 431,596,822 RAC: 0 |
Tested Theory Application today Valid (56) · Invalid (0) · Error (383) Those which got error it say Exit status -1073740791 (0xC0000409) STATUS_STACK_BUFFER_OVERRUN Stderr 2016-11-20 17:02:48 (11452): VM Heartbeat file specified, but missing. 2016-11-20 17:02:48 (11452): VM Heartbeat file specified, but missing file system status. (errno = '2') |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1311 Credit: 97,555,835 RAC: 104,823 |
Tested Theory Application today Looks like your linux did good with these. So far I got 20+ Valids and 5 Invalids I also have vLHC's and some GPU's at the same time so the *heartbeat* problem I had on the 5 Invalids was just typical with VB and my DSL and when more than one or 2 VB tasks try starting at the same time. It isn't the Ram or CPU (all Windows) but my quads just don't like starting several at the same time here or vLHC So since I am usually watching all of mine I can make sure they start a new one without the problem. (I space my tasks out so they all run several minutes apart) VB of any type will have to get past the 12 minute mark then you are pretty safe and then in the next approx 8 minutes it will finish doing the *X509 credentials* and the HTCondor Ping then you know it is going to run to the Valid finish. Of course doing that is probably not something the average cruncher wants to do. 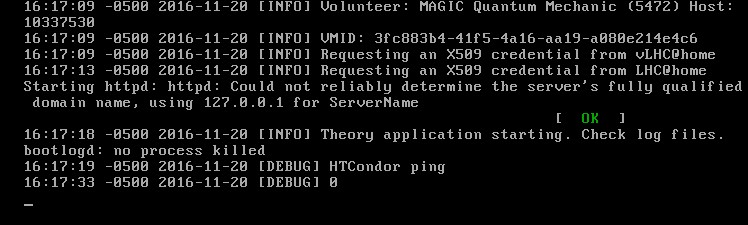 Volunteer Mad Scientist For Life unbelievable are you trying to promote linux again? |
|
Send message Joined: 9 Jan 15 Posts: 151 Credit: 431,596,822 RAC: 0 |
Yea did a check now and can´t found any error message from todays task, looks like they solve it. I compare with vLHC task as they use same version and both project works just fine now both of them. So they did take another turn from yesterday Valid (334) · Invalid (0) · Error (387) Start and suspend is fine here same as at vLHC but i notice that i got a lot postponed do to high cpu usage when it started other task. I saw a peak and hit 100% so they got interrupted when it saved data.They resume after a restart, no data lost. Only one host now is unable to run these task now. It´s a win 10 host with vpn on. I will suspend that host. |
|
Send message Joined: 2 May 07 Posts: 2304 Credit: 179,727,092 RAC: 20,376 |
https://lhcathome/vLHCathome work on this Computer. https://lhcathome.cern.ch/vLHCathome/result.php?resultid=6885610 https://lhcathome/lhcathome got this Error: 206 - Dataset name or extension to long. <core_client_version>7.6.22</core_client_version> <![CDATA[ <message> Der Dateiname oder die Erweiterung ist zu lang. (0xce) - exit code 206 (0xce) </message> <stderr_txt> Had always made a reset and deattach and attach for work with the other Version. 2016-11-22 14:39:35 (6444): Guest Log: [INFO] VMID: 3fc883b4-41f5-4a16-aa19-a080e214e4c6 2016-11-22 14:39:35 (6444): Guest Log: [INFO] Requesting an X509 credential from vLHC@home 2016-11-22 14:39:45 (6444): Guest Log: [INFO] Requesting an X509 credential from LHC@home 2016-11-22 14:39:45 (6444): Guest Log: [INFO] Theory application starting. Check log files. 2016-11-22 14:39:45 (6444): Guest Log: [DEBUG] HTCondor ping 2016-11-22 14:39:45 (6444): Guest Log: [DEBUG] 139 2016-11-22 14:39:45 (6444): Guest Log: [DEBUG] 11/22/16 14:39:16 recognized DC_NOP as command name, using command 60011. 2016-11-22 14:39:45 (6444): Guest Log: [ERROR] Could not ping HTCondor. 2016-11-22 14:39:45 (6444): Guest Log: [INFO] Shutting Down. 2016-11-22 14:39:45 (6444): VM Completion File Detected. 2016-11-22 14:39:45 (6444): VM Completion Message: Could not ping HTCondor. . 2016-11-22 14:39:45 (6444): Powering off VM. 2016-11-22 14:39:47 (6444): Successfully stopped VM. 2016-11-22 14:39:58 (6444): Deregistering VM. (boinc_26050d705340e1c5, slot#3) 2016-11-22 14:40:06 (6444): Removing virtual disk drive(s) from VM. 2016-11-22 14:40:06 (6444): Removing network bandwidth throttle group from VM. 2016-11-22 14:40:06 (6444): Removing storage controller(s) from VM. 2016-11-22 14:40:06 (6444): Removing VM from VirtualBox. 14:40:16 (6444): called boinc_finish(206) </stderr_txt> ]]> |
|
Andrew Sanchez Send message Joined: 10 Apr 14 Posts: 5 Credit: 1,106,142 RAC: 0 |
I have 2 Windows10 machines that i just migrated back to this site. Seems like everything is looking good so far. Had a little glitch on one of the machines when it tried to start 2 tasks simultaneously, but that has happened before and the remedy is just staggering my task startups. I was wondering, though. Will our credit from vLHC be migrated over to our accounts here? I was 44K credits from the 1M mark and i was looking forward to the milestone. (Obviously its not TOO big of a deal or i would have just stayed at vLHC until i hit my mark. But still...) |
|
Ray Murray Send message Joined: 29 Sep 04 Posts: 281 Credit: 11,888,115 RAC: 0 |
Hi Andrew, Work will still be available from the other site for an, as yet undefined, period until most users have migrated (back?) over here so you can continue to contribute there, and here, until such time as the other site is shut down so you may yet reach that milestone. I am sure there will be discussion on whether to merge project credits or keep them separate, and user input will be sought on that according to Laurence's comprehensive reply when I posed that question yesterday. Just noticed that the Moderator position I held at vLHC has followed me over here 8¬) |
|
Laurence Send message Joined: 20 Jun 14 Posts: 431 Credit: 256,236 RAC: 58 |
If this is what is wanted then we can try to do it. The vLHC project will have to stop running tasks first. The main thing is that the credit is safe. Whether it is in one project or another, a result has been produced and which is attributed to someone. |
|
Send message Joined: 5 Nov 15 Posts: 144 Credit: 6,301,268 RAC: 0 |
I was able to reproduce heartbeat errors on the Core2 Duo by turning down the clock frequency till the VBox machines would start to lose their real time clock and have to match it to the host clock. So Theories VM's aren't fault tolerant to too much loss of processing power. If the CPU percentages in task manager of a Theories VM are regularly dropping below 5% on an Intel 2nd gen because you use the machine for competing purposes, you can see the Theories VM error out with heartbeat error code. Quantum's solution of spacing out their start avoids this issue. Always having one free CPU core would likely solve it, possible perm assigning a above normal priority to the VBOX service/daemon might fix it. |
|
Laurence Send message Joined: 20 Jun 14 Posts: 431 Credit: 256,236 RAC: 58 |
Thanks for this feedback, it is really useful. We can see what we can do about this. EDIT: you should join our dev project :) |
|
Magic Quantum Mechanic Send message Joined: 24 Oct 04 Posts: 1311 Credit: 97,555,835 RAC: 104,823 |
You're welcome Marmot Another thing I have to do (in case I didn't mention this on one of the threads) is that I have to start these VB tasks running completely which means beyond the HTCondor ping before I do any other d'ling like the hundreds of Einstein GPU tasks/bins. I have watched this happen several times and VB and my DSL connection have problems if I am also trying to d/l those other GPU tasks at the same time. So since the last time I caught that I make sure my VB tasks get past the HTCondor ping before I try d/ling any of those other tasks. You can watch that using tasks VM Console Volunteer Mad Scientist For Life unbelievable are you trying to promote linux again? |
|
Send message Joined: 19 Feb 08 Posts: 708 Credit: 4,336,250 RAC: 0 |
I finally have 2 Theory simulations on the Windows 10 PC, my fastest machine. But where can I see the MCPLOTs? Tullio |

©2026 CERN