
Message boards : Number crunching : Tasks exceeding disk limit
Message board moderation
| Author | Message |
|---|---|
|
Send message Joined: 28 Sep 04 Posts: 817 Credit: 66,891,274 RAC: 30,593 |
A load of new tasks just loaded. In about 25 minutes at least some of them are creating an error "exceeding disk limit", message on Boinc Manager says: 31311 LHC@home 1.0 2.10.2014 20:03:16 Aborting task w-b3_26000_job.HLLHC_b3_26000.0732__1__s__62.31_60.32__11_13__5__10.5883_1_sixvf_boinc6_1: exceeded disk limit: 199.54MB > 190.73MB So far I have 4 of 4 finished ones with this kind of error, here is one of them : http://lhcathomeclassic.cern.ch/sixtrack/result.php?resultid=44495100 
|
 Ananas AnanasSend message Joined: 17 Jul 05 Posts: 102 Credit: 542,016 RAC: 0 |
Yepp, that's why I came here too - and while watching what happens, I understood, why the CPU usage is so low in the startup phase : it creates and grows a lot of "fort.##" files simultanously, probably causing I/O-waits. Aborting task w-b3_-26000_job.HLLHC_b3_-26000.0732__1__s__62.31_60.32__15_17__5__28.2354_1_sixvf_boinc116_1: exceeded disk limit: 272.38MB > 190.73MB One current result has 72 fort.## files, 32 of them keep growing fast (~5MB each at the moment), total slot size currently ~160MB so it will sure crash soon. update : 6.3MB each, 200MB total slot (which already violates the limit) |
|
Send message Joined: 28 Sep 04 Posts: 817 Credit: 66,891,274 RAC: 30,593 |
^Yep, I see that too. Some of the tasks finish before they crash, in a few minutes. Probably because of unstable beam conditions. Edit: the number of tasks out in the field is increasing fast.
|
|
Ray Murray Send message Joined: 29 Sep 04 Posts: 281 Credit: 11,888,115 RAC: 0 |
This one, at a little over half the initial estimated time, is my longest one of these to make it to completion. Another only lasted a couple of mins so probably never really got started. forts 85-90 grew to around 12MB each. Missed some that have just errored but watched one whose forts 61-90 all grew to exactly the same size of just over 7,00kB which was enough to push it over the edge. All the erroring ones are of the w-b3_xx000_job.HLLHC.... variety. NNT for now until I flush these through and let the known good ones run and allow the cache to run dry. Hopefully these duff wus will all be cleared out by morning. I've also been neglecting vLHC while there was work here so I'll give that some air. |
|
Send message Joined: 15 Jul 05 Posts: 27 Credit: 2,675,621 RAC: 0 |
count me in, 397 LHC@home 1.0 02.10.2014 21:51:31 Aborting task w-b3_-14000_job.HLLHC_b3_-14000.0732__2__s__62.31_60.32__13_15__5__7.05884_1_sixvf_boinc304_3: exceeded disk limit: 209.22MB > 190.73MB Looks like we have some bad WU http://lhcathomeclassic.cern.ch/sixtrack/workunit.php?wuid=21130329 http://lhcathomeclassic.cern.ch/sixtrack/workunit.php?wuid=21124227 http://lhcathomeclassic.cern.ch/sixtrack/workunit.php?wuid=21129470 all WU have more then one result with 196 (0xc4) EXIT_DISK_LIMIT_EXCEEDED And it's OS independent. On Windows also the "BOINC Windows Runtime Debugger" is started. Matthias |
|
Send message Joined: 26 Nov 05 Posts: 39 Credit: 435,308 RAC: 0 |
Just started happen, other WU cruncher fine. What is this? 10/2/2014 8:23:33 PM | LHC@home 1.0 | Aborting task w-b3_-10000_job.HLLHC_b3_-10000.0732__1__s__62.31_60.32__11_13__5__24.7059_1_sixvf_boinc1442_1: exceeded disk limit: 198.54MB > 190.73MB http://lhcathomeclassic.cern.ch/sixtrack/result.php?resultid=44587584 10/2/2014 11:14:44 PM | LHC@home 1.0 | Aborting task w-b3_-16000_job.HLLHC_b3_-16000.0732__4__s__62.31_60.32__13_15__5__38.8236_1_sixvf_boinc822_4: exceeded disk limit: 200.23MB > 190.73MB http://lhcathomeclassic.cern.ch/sixtrack/result.php?resultid=44587584 BOINC dIsk preferences are to use at most 50% of total disk space (size allocated 12 GB), use less than 100GB (actual in-use: 0.75 GB), leave at most 0.25 GB free (0.8 GB actual free space on HDD) - but event log shows: 10/2/2014 1:37:05 AM | | max disk usage: 1.26GB (????) Could the output file be exceeding 1/2 GB in size? I'm gonna deep six these WU's until condition-red returns to safer yellow alert. EDIT: my stupid; event log shows error tripped threshold 190.73MB. Furthermore, max disk usage 1.26GB = allocated - used - 0.25 GB specified reserve |
jay Send message Joined: 10 Aug 07 Posts: 60 Credit: 837,760 RAC: 0 |
Greetings, Also getting a task result of "Maximum disk usage exceeded". Is there a patch we can make to allow more disk space? Or, is this embedded in the task code?? I'm getting these around 15 to 20 minutes into the tasks. Thanks, Jay -- edit-- PS The disk limit does not seem to be related to the BOINC disk resource limit that the user sets up. ( I have >70 GB allocated for BOINC, only 1.7 used. Atlas had used up a large pre-allocated disk space...) |
|
jay Send message Joined: 10 Aug 07 Posts: 60 Credit: 837,760 RAC: 0 |
Another weird thing.... I looked at the co-pilots of the WU that went - over-limit for me. of the 30, I only saw one wu that was sent to a client that did not fail. http://lhcathomeclassic.cern.ch/sixtrack/workunit.php?wuid=21177447 I wonder why it didn't have the problem.. Jay |
|
Send message Joined: 28 Jul 05 Posts: 42 Credit: 767,068 RAC: 0 |
Jay, another weird thing is the result showing as pending has now run time, the first time I have ever seen this. I also have 6 results that have exited with extending the disk limit. Ranging between 1000 and 1500 seconds run-time  Have A Crunching Good day |
|
Send message Joined: 26 Nov 05 Posts: 39 Credit: 435,308 RAC: 0 |
What I un'erstan'in max disk overflow is project specified threshold - its obviously not a client specified parameter. Why is LHC overflowing its disks: dunno. What's truly weird, is that after I posted, I got the white screen of death message - all links main page - intimated project is down - within a couple minutes everything was all peachy keen - as if 'what happen?' - and none of the servers on status page intimate any, nada, prollem. I'm not saying its grumpkins and snarks. But its grumpkins and snarks. Given that overflowed WU seem to complete by wingmen, maybe there's some sort of 'seed' parameter implemented in the cruncher, i.e., varies the crunching slightly. Either that, or its a precision issue, i.e., 2+2=4 on many machines and eventually they overflow, but on other machines 2+2 = 3.5 and they can complete the WU w/ out overflowing. |
|
Send message Joined: 27 Oct 07 Posts: 186 Credit: 3,297,640 RAC: 0 |
The w-b3_ tasks are sent by the server with this line in the workunit definition: <rsc_disk_bound> 200000000 - decimal 200 MB. While running, working files fort.61 thru fort.90 seem to start growing exponentially: this screengrab was taken at about 50% progress. 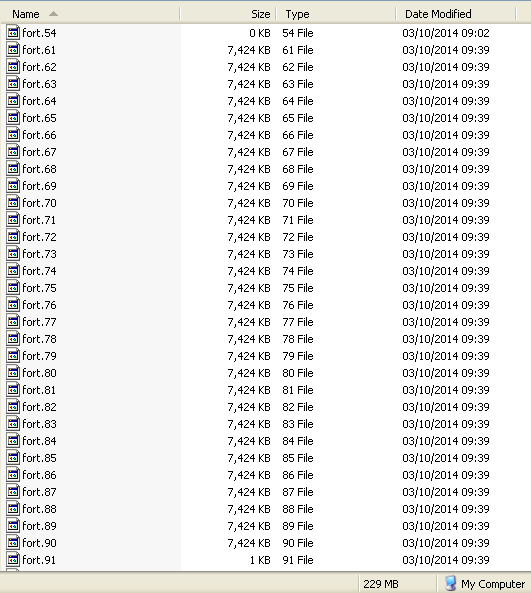 With a disk usage of 229 MB already for those 30 files, BOINC should have aborted the task already - and did so shortly afterwards. |
|
Send message Joined: 11 Dec 05 Posts: 4 Credit: 1,077,763 RAC: 0 |
I am seeing lot of errors too (example): Name w-b3_-22000_job.HLLHC_b3_-22000.0732__11__s__62.31_60.32__11_13__5__44.1178_1_sixvf_boinc3935_2 Workunit 21232197 Created 3 Oct 2014, 11:42:05 UTC Sent 3 Oct 2014, 13:37:22 UTC Received 3 Oct 2014, 16:22:06 UTC Server state Over Outcome Computation error Client state Compute error Exit status 196 (0xc4) EXIT_DISK_LIMIT_EXCEEDED Computer ID 10315741 Report deadline 11 Oct 2014, 5:09:36 UTC Run time 4,885.56 CPU time 4,349.03 Validate state Invalid Credit 0.00 Application version SixTrack v451.07 (pni) |
|
Send message Joined: 15 Jul 05 Posts: 27 Credit: 2,675,621 RAC: 0 |
some more results 1328 LHC@home 1.0 03.10.2014 14:17:43 Aborting task w-b3_-12000_job.HLLHC_b3_-12000.0732__3__s__62.31_60.32__13_15__5__14.1177_1_sixvf_boinc558_3: exceeded disk limit: 197.24MB > 190.73MB 1392 LHC@home 1.0 03.10.2014 14:47:45 Aborting task w-b3_30000_job.HLLHC_b3_30000.0732__3__s__62.31_60.32__15_17__5__47.6472_1_sixvf_boinc1916_4: exceeded disk limit: 192.40MB > 190.73MB 1427 LHC@home 1.0 03.10.2014 14:52:45 Aborting task w-b3_24000_job.HLLHC_b3_24000.0732__4__s__62.31_60.32__11_13__5__75.8825_1_sixvf_boinc2141_2: exceeded disk limit: 213.06MB > 190.73MB 1471 LHC@home 1.0 03.10.2014 15:22:49 Aborting task w-b3_0_job.HLLHC_b3_0.0732__13__s__62.31_60.32__11_13__5__10.5883_1_sixvf_boinc4388_0: exceeded disk limit: 193.56MB > 190.73MB 1507 LHC@home 1.0 03.10.2014 15:52:52 Aborting task w-b3_4000_job.HLLHC_b3_4000.0732__8__s__62.31_60.32__13_15__5__67.059_1_sixvf_boinc3137_3: exceeded disk limit: 202.94MB > 190.73MB 1508 LHC@home 1.0 03.10.2014 15:52:52 Aborting task w-b3_-24000_job.HLLHC_b3_-24000.0732__10__s__62.31_60.32__11_13__5__15.8824_1_sixvf_boinc3676_3: exceeded disk limit: 191.12MB > 190.73MB 1546 LHC@home 1.0 03.10.2014 16:27:55 Aborting task w-b3_-22000_job.HLLHC_b3_-22000.0732__10__s__62.31_60.32__13_15__5__63.5296_1_sixvf_boinc3746_2: exceeded disk limit: 216.95MB > 190.73MB example WU http://lhcathomeclassic.cern.ch/sixtrack/workunit.php?wuid=21252862 some result actual finished successful. Matthias |
|
Send message Joined: 27 Sep 04 Posts: 111 Credit: 8,606,185 RAC: 7 |
Same here Lots of Disk Space Exceeded errors, all on w-3b* WUs But I've also got some w-3b WUs that complete successfully <shrug>  
|
|
Send message Joined: 26 Nov 05 Posts: 39 Credit: 435,308 RAC: 0 |
project completion: 42% @ 2.6666 hrs project size = 6.20MB (6.21 slack) slct size = 191MB (192 slack) slot init_data.xml <rsc_memory_bound>100000000.000000</rsc_memory_bound> <rsc_disk_bound>200000000.000000</rsc_disk_bound> I change disk value to 400000000 and restart BOINC Manager. I wait short time and Now at 43.5% complete and slot size 195MB (196 slack), project size 6.20MB (6.21 slack). At 2.8 hrs it blow up: 10/3/2014 2:05:45 PM | LHC@home 1.0 | Aborting task w-b3_30000_job.HLLHC_b3_30000.0732__4__s__62.31_60.32__11_13__5__58.2354_1_sixvf_boinc2072_4: exceeded disk limit: 198.24MB > 190.73MB http://lhcathomeclassic.cern.ch/sixtrack/result.php?resultid=44914176 Dunno. I remember having to edit init for Lattice. Forgot what was done there. Mebbe hafta restart computer after edit init.xml? |
|
Send message Joined: 27 Oct 07 Posts: 186 Credit: 3,297,640 RAC: 0 |
I change disk value to 400000000 and restart. You would probably need to make that change in client_state.xml rather than init_data.xml Very much at your own risk. |
|
Send message Joined: 17 Jun 13 Posts: 8 Credit: 6,548,286 RAC: 0 |
I have racked up 240 failed tasks now due to "Maximum disk usage exceeded"... I am temporarily disabling this project until this is fixed. Too many resources wasted here... |
|
Send message Joined: 26 Nov 05 Posts: 39 Credit: 435,308 RAC: 0 |
I change disk value to 400000000 and restart. I just discovered that init_data.xml gets overwritten on BOINC Manager exit. I discovered that client_state.xml contains entry for LHC WU. I made aforementioned change to both files now. That's schizo coding; if the slot doesn't get created until a WU is started - the slot contains the init_data.xml - but the client_state.xml is the driver (overwriting init_data.xml edit?). We be crunching another one now. We'll see if it finishes. If so, there's the validation issue subsequent; if no wingman can complete the WU w/o abend due to disk overflow. |
|
Send message Joined: 6 Oct 05 Posts: 18 Credit: 952,091 RAC: 0 |
Got one of these myself yesterday..with over 13 GB of the 20 allotted to BOINC still available...  |
|
Send message Joined: 26 Nov 05 Posts: 39 Credit: 435,308 RAC: 0 |
After 3.25 hrs still crunchin' w/ 30 forts comprising 202MB for grantotal of 220 and still growin' - but there be 26 forts of 0kb so I've no idea how this'll play out. Its chunkin' and ka-thunkin' and whirrin' and blinkin' and flashin' and beepin' and boppin'....the little hamster wheel be whinin' something fierce - we be needin' to put some beef tallow on the bearing hub. EDIT: at 2340 UTC its crunched 255MB with headroom to 381MB - per aforementioned tweak to client_state.xml - at which point I can still give him 'nother 177MB That notwithstanding, I'm a gonna hafta suspend all other projects w/ no new work - no body else'll have room to run. |

©2026 CERN