
Message boards : Number crunching : New computer database entry created on each connect
Message board moderation
Previous · 1 · 2 · 3 · Next
| Author | Message |
|---|---|
|
Send message Joined: 14 Jul 05 Posts: 275 Credit: 49,291 RAC: 0 |
Problem is still happening! (and there is another thread about it) This problem is making server load worse (host table in database is probably super-big by now) and also I think this is the reason why there are no stats. XML stats for hosts would be also extremely large. |
|
Send message Joined: 14 Jul 05 Posts: 275 Credit: 49,291 RAC: 0 |
So a detailed method to stop this happening is as follows: This method works perfectly. But why is host id 0 in the first place? This is obviously a problem that comes from server, and affects server. I don't care having a hundred hosts on my account, but server is affected by having to store two million hosts on database. So it's admins who have to fix it, and who would be interested in having it fixed. |
|
Send message Joined: 26 Aug 05 Posts: 18 Credit: 37,965 RAC: 0 |
Problem is still happening! (and there is another thread about it) Since there seems to be no post from someone _not_ experiencing the problem, I thought I'd point out that this not happening to everyone. It might be interesting to see if there are any patterns to the host duplication. . . I have never had any of my hosts duplicated for no reason. My main host is using client Version 5.4.11 on windows xp. All of my hosts since the problem started have been windows of various versions. |
|
Send message Joined: 26 Nov 05 Posts: 16 Credit: 14,707 RAC: 0 |
Since there seems to be no post from someone _not_ experiencing the problem, I thought I'd point out that this not happening to everyone. It might be interesting to see if there are any patterns to the host duplication. . .I think, the point is the hostid "0" stored at the client. There has been a combination of some newer version of the client with an old version of the server software, that could create such an entry. In the meantime the client was updated further and the server software too. "Uptodate" software will correct the entry - but both sides have to be updated. Now LHC seems to be the project with the oldest server version still around. The only other servers I've seen this error are Sztaki and Leiden which too have rather old software at the server. Norbert |
|
Send message Joined: 29 Sep 04 Posts: 3 Credit: 284,021 RAC: 0 |
For me this problem occured when i did a clean install of the windows. Until this happend it was fine. This was with 5.4.9 on a works p.c. and also 5.4.11 on my home one. Both times the above fix worked for me although in the boinc manager the host total graph on the stats tab is not updating. Could it be that this is partially to blame for the stats problem? Phanteks Luxe 2, AMD 3700x, MSI 2070 super X trio, 32gb Corsiar vengance RGB pro, watercooled.  
|
|
Send message Joined: 13 Jul 05 Posts: 456 Credit: 75,142 RAC: 0 |
Looking at people's reports of this, here and in other threads, I think the general experience is that this happens to new hosts. By "new hosts" I include hosts that are genuinely new to LHC, hosts that return after a detach/attach, and hosts where the entire BOINC directory is re-installed, or after a clean re-install of the operating system. By "new hosts" I do not include hosts where there has been a project reset, nor hosts where BOINC has been re-installed into an existing directory keeping the previous data files intact, especially client_state.xml Once a host is running nicely then the problem does not seem to happen again with that host, which is why many users have not seen this issue. If anyone has seen an example that proves me wrong, please let us know. I also agree with the suggestions that this problem may be caused by the fact that LHC is running old server software; and that this problem may itself be the cause of the "technical difficulty" in exporting XML stats. R~~ |
|
Send message Joined: 13 Jul 05 Posts: 456 Credit: 75,142 RAC: 0 |
After the bug has been fixed, and no new ghost hosts are being created, we then have the issue of what to do with the million hosts in the database - the "megaghost host" problem. In a world where participants all read these boards, the project admins would simply ask each participant to use merge to tidy up their own hosts. You can do a page full at a time using the "select all" feature, so distributed over the users this is not too big a job. However, back to the real world. Many participants don't read these boards. Some who did read these boards have left the project and won't be back. Some who do read these boards will just not get round to finding time to clean up, a few will get stroppy and think "this is not my job, I donate cpu time I don't expect to donate my own time too". All the other fixes have costs to the participants. Fix 1 Delete all hosts that have never returned work / never made contact since creation / etc and that were created before the fix was effective. This will mean that someone who created a host but never did anything else will find that host changes its identity when they next try. It will look to the participant like another instance of the same bug. It will also mean that a few participants will lose much loved hosts that they have kept for sentimental reasons (they like to see the low hostid, they like to remember the 142.43 cobblestones they crunched on that old laptop, whatever). Don't discount these as nonsense - this kind of sentimental payoff is one of the things that keeps people donating. DC projects (outside of BOINC) that have not offered host tracking and other stats facilities have not kept donor support. Fix 2 Merge all hosts that etc etc This will merge some machines that are in fact different. How much does this matter? To the project, not at all as all the merged machines will be ghosts anyway. To the participant it might matter, as they wanted to keep the 142.43 cobblestones from the laptop separate from their 100k desktop. It might also matter to someone who uses the host stats - a user who genuinely has 100 identical boxes (ksba for example, or any other institutional donor) would find that the historical credit of all 100 boxes was shown against a single box. This in turn would not look plausible and they might get accused of cheating. Fix 3 Delete absolutely all hosts, whether active or not, during a gap where there are no work untis outstanding. In fact, while doing that, start with a clean database and simply re-import the credit and RAC for each user & team. This would get rid of a number of other accumulated anomalies in the db. Admins would have to be very sure to have a backup copy of the user and team credits - preferably several copies. Ideally, they could arrange to have exported the XML stats beforehand so that BoincStats, BoincSynergy - especially if it is possible to provide XML stats for users & teams without generating the hosts stats (which would be horribly long) Next time users connected they would find they had new host ids, and all hosts would have restarted from zero stats - only the user and team stats would show the past. This would have to be notified well in advance, with notes on the main page and in these forums, otherwise this will look like a repeat of the same old bug. There would probably be a project outage while the admins did the work, so users would be warned before the outage that host info would be lost when they came back. Does anyone have any other ideas for how to clean up after the bug is fixed? I hope someone has a better idea than any of mine, as I don't like any of them. It seems to me that finding the bug will be the easy part (once a professional starts looking). Cleaning up the mess the bug made will be harder. River~~ 
|
|
Send message Joined: 29 Nov 05 Posts: 8 Credit: 105,015 RAC: 0 |
In a world where participants all read these boards, the project admins would simply ask each participant to use merge to tidy up their own hosts. You can do a page full at a time using the "select all" feature, so distributed over the users this is not too big a job. How true - imho, a lot of those who post don't read these boards either, judging by the number of threads on this same subject...I know, I'm bound to get caught out myself on this now I've mentioned it :-) Does anyone have any other ideas for how to clean up after the bug is fixed? I hope someone has a better idea than any of mine, as I don't like any of them. I think it's may already been done on other prujects - I found this thread some time ago on the Rosetta boards referring to a patch to fix it. One of the entries by Halifax Lad refers. The above thread also casts doubt on the theory that BAM is to blame. As for getting people to delete the extra host ids, how about having an announcement put up on the LHC@home homepage - maybe also see about getting something put on the BOINC homepage. Failing that, maybe if you did implement a software solution, maybe it should do something like merge all sets of apparently identical hosts where there are more than two of them - you would still have excess hosts, but the risk of getting rid of genuine hosts could be significantly less. [edit]BTW, in order to close BOINC Manager before doing the edits mentioned in the posts above, you just need to open the BOINC Manager window and click on File then Exit - not so messy as using the Task Manager. This works for Windows anyway, don't know about any other OS.[/edit] Live long and prosper 
|
 Keck_Komputers Keck_KomputersSend message Joined: 1 Sep 04 Posts: 275 Credit: 2,652,452 RAC: 0 |
So a detailed method to stop this happening is as follows: The version of the server software that was out when this project last updated had a bug where when a new hostid was assigned it was not sent to the host. The previous admins left before this bug was found and killed. Since the host does not get the newly assigned ID the next time it connects the server thinks the host needs a new ID and assigns another that is not passed to the client and the cycle repeats. That is also why this fix works, now the host is reporting an acceptable ID to the server so the sever no longer tries to assign it a new one. BOINC WIKI   BOINCing since 2002/12/8 |
|
Send message Joined: 13 Jul 05 Posts: 456 Credit: 75,142 RAC: 0 |
... That is also why this fix works, now the host is reporting an acceptable ID to the server so the sever no longer tries to assign it a new one. Thanks John, it is always nice to have theoretical support for an empirical hack :) Gold stars to all those hackers who predicted it would turn out to be a server bug without knowing the code. R~~ |
|
Send message Joined: 13 Jul 05 Posts: 456 Credit: 75,142 RAC: 0 |
... I found this thread some time ago on the Rosetta boards referring to a patch to fix it. Good reference, thanks That thread also makes the useful point that even tho the BAM is not to blame, use of the BAM can make the situation worse if it promotes more frequent access between client and server.
imho, doing all of that will not get even half the afflicted users to do anything. BOINC is promoted as a "set and forget" system and it is we, who like to keep careful watch on our machines and these boards, it is we who are the minority.
I like this - especially if we replace "two" with the largest integer we think we can get away with and not slug the system. Three? Four? Seven?
Only works for windows if you are not running as a service. I agree you should not use the task manager. R~~ |
|
Send message Joined: 13 Jul 05 Posts: 170 Credit: 15,020,549 RAC: 0 |
Failing that, maybe if you did implement a software solution, maybe it should do something like merge all sets of apparently identical hosts where there are more than two of them - you would still have excess hosts, but the risk of getting rid of genuine hosts could be significantly less. How about merging all sets of apparently identical hosts with exactly one result ever assigned to them? That would focus on the current ghost hosts, though probably they should also have to be at least a month old to give bona fide machines enough chances to get work. Henry |
|
Send message Joined: 14 Jul 05 Posts: 275 Credit: 49,291 RAC: 0 |
Failing that, maybe if you did implement a software solution, maybe it should do something like merge all sets of apparently identical hosts where there are more than two of them - you would still have excess hosts, but the risk of getting rid of genuine hosts could be significantly less. There are thousands of hosts with 0 results assigned. In fact, that is the majority. |
|
Send message Joined: 13 Jul 05 Posts: 170 Credit: 15,020,549 RAC: 0 |
How about merging all sets of apparently identical hosts with exactly one result ever assigned to them? That would focus on the current ghost hosts, though probably they should also have to be at least a month old to give bona fide machines enough chances to get work. Oops - the one time it happened to me, I'm sure each ghost had one results associated with it. "Merge all sets of apparently identical hosts with zero or one result, and more than a month old" then. My point is that you don't have to risk messing up people's farms when cleaning up, since bona fide machines will have an extended history while the bogus ones won't. Henry |
|
Send message Joined: 28 Sep 05 Posts: 21 Credit: 11,715 RAC: 0 |
I am not having this multiple host problem, I've looked at my client_state.xml and the host ID is the same one I've always had. What's interesting is the messages Boinc Manager gave when connecting today to get work. I'm using the Boinc 5.7.5 Manager and the messages are slightly different. On Boinc startup: 11/24/2006 3:24:41 AM||General prefs: from SETI@home (last modified 2006-11-18 12:40:14) 11/24/2006 3:24:41 AM||Host location: none 11/24/2006 3:24:41 AM||General prefs: using your defaults 11/24/2006 3:24:44 AM||Running CPU benchmarks And much later when I discovered work was available at LHC: 11/25/2006 12:02:28 PM|lhcathome|Fetching scheduler list 11/25/2006 12:02:34 PM|lhcathome|Master file download succeeded 11/25/2006 12:02:39 PM|lhcathome|Sending scheduler request: Requested by user 11/25/2006 12:02:39 PM|lhcathome|Requesting 12332 seconds of new work 11/25/2006 12:02:44 PM|lhcathome|Scheduler RPC succeeded [server version 502] 11/25/2006 12:02:44 PM|lhcathome|New host venue: 0 11/25/2006 12:02:44 PM|lhcathome|Deferring scheduler requests for 7 seconds 11/25/2006 12:02:46 PM|lhcathome|Started download of file ... <downloads - I deleted these lines> 11/25/2006 12:05:59 PM|lhcathome|Sending scheduler request: Requested by user 11/25/2006 12:05:59 PM|lhcathome|(not requesting new work or reporting completed tasks) 11/25/2006 12:06:04 PM|lhcathome|Scheduler RPC succeeded [server version 502] 11/25/2006 12:06:04 PM||General prefs: from lhcathome (last modified 2006-11-25 12:05:49) 11/25/2006 12:06:04 PM||Host location: 0 11/25/2006 12:06:04 PM||General prefs: no separate prefs for 0; using your defaults 11/25/2006 12:06:04 PM|lhcathome|Deferring scheduler requests for 7 seconds 11/25/2006 12:06:14 PM|lhcathome|Sending scheduler request: To fetch work 11/25/2006 12:06:14 PM|lhcathome|Requesting 94930 seconds of new work 11/25/2006 12:06:19 PM|lhcathome|Scheduler RPC succeeded [server version 502] 11/25/2006 12:06:19 PM|lhcathome|Deferring scheduler requests for 7 seconds ... <more downloads> Note the Host is listed as 'none' at startup and when connecting to LHC it is 0, I haven't seen this message before in the official Boinc Manager, I guess the message is something added to the 5.7.5 Manager. It did not however change the Host ID in the client_state.xml file, I've still got the same one I always did. I've also never used an account manager. This might better be reported to the Boinc Manager beta forum but I thought it might be relevant here. It has caused no problem for me to solve and I don't know if it's even helpful here, I just thought I'd report that it happened. |
|
Saenger Send message Joined: 13 Jul 05 Posts: 64 Credit: 501,223 RAC: 0 |
I have the same host since I started under Linux some time ago (Created 16 May 2006 19:39:11 UTC). No ghost host whatsoever, and a lot of contact since, and even some WUs crunched. I never merged any host, only deleted my old Windoze puter to keep the list short, but that was about half a year ago. Grüße vom Sänger 
|
|
Send message Joined: 1 Sep 04 Posts: 36 Credit: 78,199 RAC: 0 |
That thread also makes the useful point that even tho the BAM is not to blame, use of the BAM can make the situation worse if it promotes more frequent access between client and server. Well... Account Managers does play an important part in this problem... Only when needed, the Scheduler-reply includes hostid. This is either for newly-attached project, there <hostid>0</hostid>, or in case <rpc_seqno> in scheduler-request is lower than rpc_seqno saved in BOINC-database, indicating copied client-installation to another computer. For LHC@home, a "normal" Scheduler-request including host-id looks something like this: <project_preferences> <resource_share>100</resource_share> <project_specific> <color_scheme>Tahiti Sunset</color_scheme> </project_specific> </project_preferences> <hostid>1234567</hostid> But, if someone has used an Account Manager to chance resource-share, the same Scheduler-request for LHC@home looks like this: <project_preferences> <resource_share>100</resource_share> </project_preferences><hostid>1234567</hostid> As you can see, there's 2 changes here. As someone probably has detected atleast in Rosetta@home, the <project_specific>-part has been "destroyed" by the Account Manager, but atleast for LHC@home this isn't really a problem. The critical part is, hostid is placed on the same line as </project_preferences>, and client therefore does not parse this part at all. Meaning, if hostid was zero on client before, it will still be zero, and with old server-code, each time you're making a scheduler-request with <hostid>0</hostid>, you'll generate a new hostid... With new server-code, Scheduling-server will also look on <host_cpid>, and if you've got a link between <host_cpid> and <hostid>, you'll re-use this hostid instead of generating a new one. Also, a quick check on SETI@home revealed <hostid> was correctly placed on another line, even in case Account Manager has "destroyed" the <project_specific>-part. While waiting on LHC@home to upgrade the server-software, the easy solution for this problem is, if you goes to the projects own pages and changes the resource-share here, you're back to the "normal" scheduler-reply, and client won't have any problem to read any possible <hostid>. "I make so many mistakes. But then just think of all the mistakes I don't make, although I might." |
|
Fuzzy Hollynoodles Send message Joined: 13 Jul 05 Posts: 51 Credit: 10,626 RAC: 0 |
Peter was so kind to give me the fix for this bug in this post, and it works. Thanks again, Peter. :-) "I'm trying to maintain a shred of dignity in this world" - Me 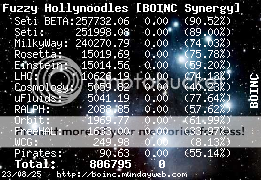
|
|
Send message Joined: 13 Jul 05 Posts: 456 Credit: 75,142 RAC: 0 |
...The critical part is, hostid is placed on the same line as </project_preferences>, and client therefore does not parse this part at all... This is a client bug then, even tho it is triggered by differing layouts in the xml. The reason I say that is that (like html), xml is supposed to be layout independent. Layout within a tag may matter sometimes (eg in tags for laid out text) but never in the space between tags (or lack of space between tags). The client should parse by tags, not by newlines. Of course, on a more pragmatic approach, you give a good exmplantion of why some software seems to provoke the bug and other software doesn't. R~~ |
|
Send message Joined: 14 Jul 05 Posts: 275 Credit: 49,291 RAC: 0 |
...The critical part is, hostid is placed on the same line as </project_preferences>, and client therefore does not parse this part at all... BOINC is using a custom-made XML parser (both in client and server code) which, among other problems, requires each tag to be in a different line. This is from the mailing list:
|

©2026 CERN